For optimal reading, please switch to desktop mode.
OpenStack Ironic operates in a curious world. Each release of Ironic introduces ever more inventive implementations of the abstractions of virtualisation. However, bare metal is wrapped up in hardware-defined concrete: devices and configurations that have no equivalent in software-defined cloud. To exist, Ironic must provide pure abstractions, but to succeed it must also offer real-world circumventions.
For decades the conventional role of an HPC system administrator has included deploying bare metal machines, sometimes at large scale. Automation becomes essential beyond trivial numbers of systems to ensure repeatability, scalability and efficiency. Thus far, that automation has evolved in domain-specific ways, loaded with simplifying assumptions that enable large-scale infrastructure to be provisioned and managed from a minimal service. Ironic is the first framework to define the provisioning of bare metal infrastructure in the paradigm of cloud.
So much for the theory: working with hardware has always been a little hairy, never as predictable or reliable as expected. Software-defined infrastructure, the method underpinning the modern mantra of agility, accelerates the interactions with hardware services by orders of magnitude. Ironic strives to deliver results in the face of unreliability (minimising the need to ask someone in the data centre to whack a machine with a large stick).
HPC Infrastructure for Seismic Analysis
As a leader in the seismic processing industry, ION Geophysical maintains a hyperscale production HPC infrastructure, and operates a phased procurement model that results in several generations of hardware being active within the production environment at any time. Field failures and replacements add further divergence. Providing a consistent software environment across multiple hardware configurations can be a challenge.
ION is migrating on-premise HPC infrastructure into an OpenStack private cloud. The OpenStack infrastructure is deployed and configured using Kayobe, a project that integrates Ironic (for hardware deployment) and Kolla-Ansible (for OpenStack deployment), all within an Ansible framework. Ansible provides a consistent interface to everything, from the physical layer to the application workloads themselves.
This journey began with some older-generation HPE SL230 compute nodes and a transfer of control to OpenStack management. Each node has two HDDs. To meet the workload requirements these are provisioned as two RAID volumes - one mirrored (for the OS) and one striped (for scratch space for the workloads).
Each node also has a hardware RAID controller, and standard practice in Ironic would be to make use of this. However, after analysing the hardware it was found that:
- The hardware RAID controller needed to be enabled via the BIOS, but the BIOS administration tool failed on many nodes because the 'personality board' had failed, preventing the tool from retrieving the server model number.
- The RAID controller required a proprietary kernel driver which was not available for recent CentOS releases. The driver was not just required for administering the controller, but for mounting the RAID volumes.
Taking these and other factors into account, it was decided that the hardware RAID controller was unusable. Thankfully, Ironic developed a software-based alternative.
Provisioning to Software RAID
Linux servers are often deployed with their root filesystem on a mirrored RAID-1 volume. This requirement exemplifies the inherent tensions within the Ironic project. The abstractions of virtualisation demand that the guest OS is treated like a black box, but the software RAID implementation is Linux-specific. However, not supporting Linux software RAID would be a limitation for the primary use case. Without losing Ironic's generalised capability, the guest OS “black box” becomes a white box in exceptional cases such as this. Recent work led by CERN has contributed software RAID support to the Ironic Train release.
The CERN team have documented the software RAID support on their tech blog.
In its initial implementation, the software RAID capability is constrained. A bare metal node is assigned a persistent software RAID configuration, applied whenever a node is cleaned and used for all instance deployments. Prior work involving the StackHPC team to develop instance-driven RAID configurations is not yet available for software RAID. However, the current driver implementation provides exactly the right amount of functionality for Kayobe's cloud infrastructure deployment.
The Method
RAID configuration in Ironic is described in greater detail in the Ironic Admin Guide. A higher-level overview is presented here.
Software RAID with UEFI boot is not supported until the Ussuri release, where it can be used in conjuction with a rootfs UUID hint stored as image meta data in a service such as Glance. For Bifrost users this means that legacy BIOS boot mode is the only choice, ruling out secure boot and NVMe devices for now.
In this case the task was to provision a large number of compute nodes with OpenStack Train, each with two physical spinning disks and configured for legacy BIOS boot mode. These were provisioned according to the OpenStack documentation with some background provided by the CERN blog article. Two RAID devices were specified in the RAID configuration set on each node; the first for the operating system, and the second for use by Nova as scratch space for VMs.
{
"logical_disks": [
{
"raid_level": "1",
"size_gb" : 100,
"controller": "software"
},
{
"raid_level": "0",
"size_gb" : "800",
"controller": "software"
}
]
}
Note that although you can use all remaining space when creating a logical disk by setting size_gb to MAX, you may wish to leave a little spare to ensure that a failed disk can be rebuilt if it is replaced by a model with marginally different capacity.
The RAID configuration was then applied with the following cleaning steps as detailed in the OpenStack documentation:
[{
"interface": "raid",
"step": "delete_configuration"
},
{
"interface": "deploy",
"step": "erase_devices_metadata"
},
{
"interface": "raid",
"step": "create_configuration"
}]
A RAID-1 device was selected for the OS so that the hypervisor would remain functional in the event of a single disk failure. RAID-0 was used for the scratch space to take advantage of the performance benefit and additional storage space offered by this configuration. It should be noted that this configuration is specific to the intended use case, and may not be optimal for all deployments.
As noted in the CERN blog article, the mdadm package was installed into the Ironic Python Agent (IPA) ramdisk for the purpose of configuring the RAID array during cleaning. mdadm was also installed into the deploy image to support the installation of the grub2 bootloader onto the physical disks for the purposes of loading the operating system from either disk should one fail. Finally, mdadm was added to the deploy image ramdisk, so that when the node booted from disk, it could pivot into the root filesystem. Although we would generally use Disk Image Builder, a simple trick for the last step is to use virt-customize:
virt-customize -a deployment_image.qcow2 --run-command 'dracut --regenerate-all -fv --mdadmconf --fstab --add=mdraid --add-driver="raid1 raid0"'
Open Source, Open Development
As an open source project, Ironic depends on a thriving user base contributing back to the project. Our experiences covered new ground: hardware not used before by the software RAID driver. Inevitably, new problems are found.
The first observation was that configuration of the RAID devices during cleaning would fail on about 25% of the nodes from a sample of 56. The nodes which failed logged the following message:
mdadm: super1.x cannot open /dev/sdXY: Device or resource busy
where X was either a or b and Y either 1 or 2, denoting the physical disk and partition number respectively. These nodes had previously been deployed with software RAID, either by Ironic or by other means.
Inspection of the kernel logs showed that in all cases, the device marked as busy had been ejected from the array by the kernel:
md: kicking non-fresh sdXY from array!
The device which had been ejected, which may or may not have been synchronised, appeared in /proc/mdstat as part of a RAID-1 array. The other drive, having been erased, was missing from the output. It was concluded that the ejected device had bypassed the cleaning steps designed to remove all previous configuration, and had later resurrected itself, thereby preventing the formation of the array during the create_configuration cleaning step.
For cleaning to succeed, a manual workaround of stopping this RAID-1 device and zeroing signatures in the superblocks was applied:
mdadm --zero-superblock /dev/sdXY
Removal of all pre-existing state greatly increased the reliability of software RAID device creation by Ironic. The remaining question was why some servers exhibited this issue and others did not. Further inspection showed that although many of the disks were old, there were no reported SMART failures, the disks passed self tests and although generally close, had not exceeded their mean time before failure (MTBF). No signs of failure were reported by the kernel in addition to the removal of a device from the array. Actively seeking errors, for example by running tools such as badblocks to exercise the entire disk media, showed that only a very small number of disks had issues. Benchmarking, burn-in and anomaly detection may have identified those devices sooner.
Further research may help us identify whether the disks that exhibit this behaviour are at fault in any other way. An additional line of investigation could be to increase thresholds such as retries and timeouts for the drives in the kernel. For now the details are noted in a bug report.
The second issue observed occurred when the nodes booted from the RAID-1 device. These nodes, running IPA and deploy images based on Centos 7.7.1908 with kernel version 3.10.0-1062, would show degraded RAID-1 arrays, with the same message seen during failed cleaning cycles:
md: kicking non-fresh sdXY from array!
A workaround for this issue was developed by running a Kayobe custom playbook against the nodes to add sdXY back into the array. In all cases the ejected device was observed to resync with the RAID device. The state of the RAID arrays is monitored using OpenStack Monasca, ingesting data from a recent release candidate of Prometheus Node Exporter containing some enhancements around MD/RAID monitoring. Software RAID status can be visualised using a simple dashboard:
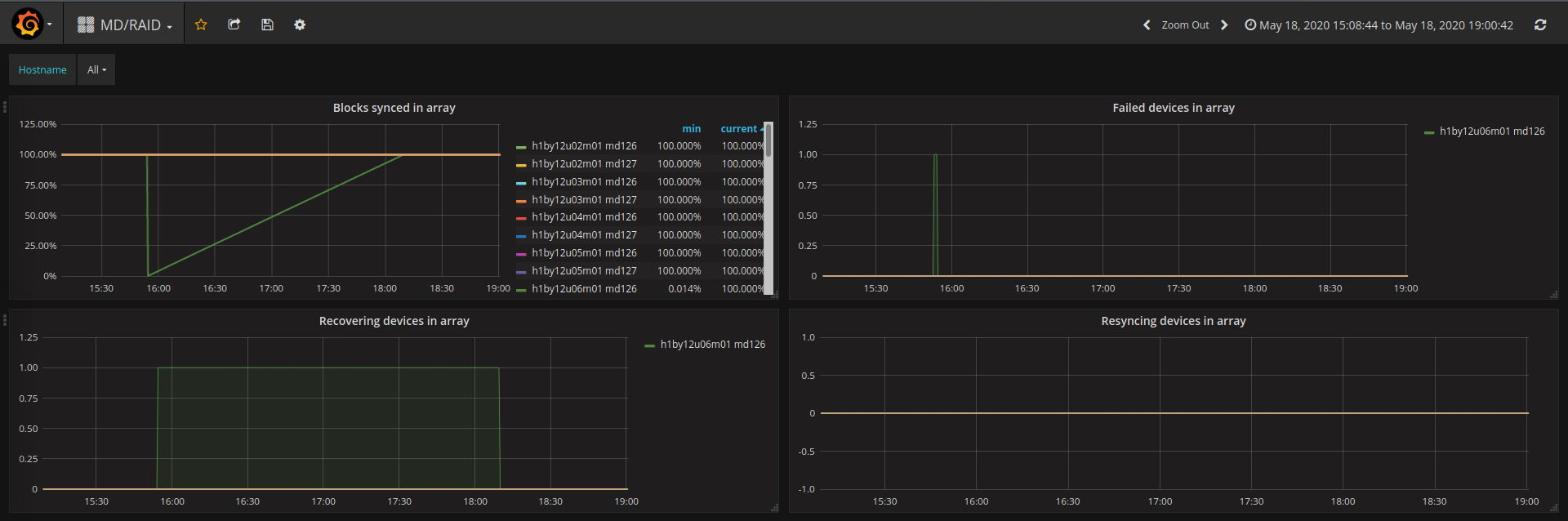
Monasca MD/RAID Grafana dashboard using data scraped from Prometheus node exporter.
The plot in the top left shows the percentage of blocks synchronised on each RAID device. A single RAID-1 array can be seen recovering after a device was forcibly failed and added back to simulate the failure and replacement of a disk. Unfortunately it is not yet possible to differentiate between the RAID-0 and RAID-1 devices on each node since Ironic does not support the name field for software RAID. The names for the RAID-0 and RAID-1 arrays therefore alternate randomly between md126 and md127. Top right: The simulated failed device is visible within seconds. This is a good metric to generate an alert from. Bottom left: The device is marked as recovering whilst the array rebuilds. Bottom right: No manual re-sync was initiated. The device is seen as recovering by MD/RAID and does not show up in this figure.
The root cause of these two issues is not yet identified, but they are likely to be connected, and relate to an interaction between these disks and the kernel MD/RAID code.
Open Source, Open Community
Software that interacts with hardware soon builds up an extensive "case law" of exceptions and workarounds. Open projects like Ironic survive and indeed thrive when users become contributors. Equivalent projects that do not draw on community contribution have ultimately fallen short.
The original contribution made by the team at CERN (and others in the OpenStack community) enabled StackHPC and ION Geophysical to deploy infrastructure for seismic processing in an optimal way. Whilst in this case we would have liked to have gone further with our own contributions, we hope that by sharing our experience we can inspire other users to get involved with the project.
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky or directly via our contact page.