For optimal reading, please switch to desktop mode.

Iron is solid and inflexible, right?
OpenStack Ironic's Deploy Templates feature brings us closer to a world where bare metal servers can be automatically configured for their workload.
In this article we discuss the Bespoke Bare Metal (slides) presentation given at the Open Infrastructure summit in Denver in April 2019.
BIOS & RAID
The most requested features driving the deploy templates work are dynamic BIOS and RAID configuration. Let's consider the state of things prior to deploy templates.
Ironic has for a long time supported a feature called cleaning. This is typically used to perform actions to sanitise hardware, but can also perform some one-off configuration tasks. There are two modes - automatic and manual. Automatic cleaning happens when a node is deprovisioned. A typical use case for automatic cleaning is shredding disks to remove sensitive data. Manual cleaning happens on demand, when a node is not in use. The following diagram shows a simplified view of the node states related to cleaning.
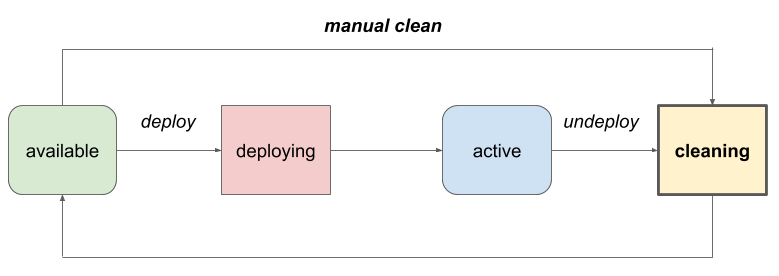
Cleaning works by executing a list of clean steps, which map to methods exposed by the Ironic driver in use. Each clean step has the following fields:
- interface: One of deploy, power, management, bios, raid
- step: Method (function) name on the driver interface
- args: Dictionary of keyword arguments
- priority: Order of execution (higher runs earlier)
BIOS
BIOS configuration support was added in the Rocky cycle. The bios driver interface provides two clean steps:
- apply_configuration: apply BIOS configuration
- factory_reset: reset BIOS configuration to factory defaults
Here is an example of a clean step that uses the BIOS driver interface to disable HyperThreading:
{
"interface": "bios",
"step": "apply_configuration",
"args": {
"settings": [
{
"name": "LogicalProc",
"value": "Disabled"
}
]
}
}
RAID
Support for RAID configuration was added in the Mitaka cycle. The raid driver interface provides two clean steps:
- create_configuration: create RAID configuration
- delete_configuration: delete all RAID virtual disks
The target RAID configuration must be set in a separate API call prior to cleaning.
{
"interface": "raid",
"step": "create_configuration",
"args": {
"create_root_volume": true,
"create_nonroot_volumes": true
}
}
Of course, support for BIOS and RAID configuration is hardware-dependent.
Limitations
While BIOS and RAID configuration triggered through cleaning can be useful, it has a number of limitations. The configuration is not integrated into Ironic node deployment, so users cannot select a configuration on demand. Cleaning is not available to Nova users, so it is accessible only to administrators. Finally, the requirement for a separate API call to set the target RAID configuration is quite clunky, and prevents the configuration of RAID in automated cleaning.
With these limitations in mind, let's consider the goals for bespoke bare metal.
Goals
We want to allow a pool of hardware to be applied to various tasks, with an optimal server configuration used for each task. Some examples:
- A Hadoop node with Just a Bunch of Disks (JBOD)
- A database server with mirrored & striped disks (RAID 10)
- A High Performance Computing (HPC) compute node, with tuned BIOS parameters
In order to avoid partitioning our hardware, we want to be able to dynamically configure these things when a bare metal instance is deployed.
We also want to make it cloudy. It should not require administrator privileges, and should be abstracted from hardware specifics. The operator should be able to control what can be configured and who can configure it. We'd also like to use existing interfaces and concepts where possible.
Recap: Scheduling in Nova
Understanding the mechanics of deploy templates requires a reasonable knowledge of how scheduling works in Nova with Ironic. The Placement service was added to Nova in the Newton cycle, and extracted into a separate project in Stein. It provides an API for tracking resource inventory & consumption, with support for both quantitative and qualitative aspects.
Let's start by introducing the key concepts in Placement.
- A Resource Provider provides an Inventory of resources of different Resource Classes
- A Resource Provider may be tagged with one or more Traits
- A Consumer may have an Allocation that consumes some of a Resource Provider’s Inventory
Scheduling Virtual Machines
In the case of Virtual Machines, these concepts map as follows:
- A Compute Node provides an Inventory of vCPU, Disk & Memory resources
- A Compute Node may be tagged with one or more Traits
- An Instance may have an Allocation that consumes some of a Compute Node’s Inventory
A hypervisor with 35GB disk, 5825MB RAM and 4 CPUs might have a resource provider inventory record in Placement accessed via GET /resource_providers/{uuid}/inventories that looks like this:
{
"inventories": {
"DISK_GB": {
"allocation_ratio": 1.0, "max_unit": 35, "min_unit": 1,
"reserved": 0, "step_size": 1, "total": 35
},
"MEMORY_MB": {
"allocation_ratio": 1.5, "max_unit": 5825, "min_unit": 1,
"reserved": 512, "step_size": 1, "total": 5825
},
"VCPU": {
"allocation_ratio": 16.0, "max_unit": 4, "min_unit": 1,
"reserved": 0, "step_size": 1, "total": 4
}
},
"resource_provider_generation": 7
}
Note that the inventory tracks all of a hypervisor's resources, whether they are consumed or not. Allocations track what has been consumed by instances.
Scheduling Bare Metal
The scheduling described above for VMs does not apply cleanly to bare metal. Bare metal nodes are indivisible units, and cannot be shared by multiple instances or overcommitted. They're either in use or not. To resolve this issue, we use Placement slightly differently with Nova and Ironic.
- A Bare Metal Node provides an Inventory of one unit of a custom resource
- A Bare Metal Node may be tagged with one or more Traits
- An Instance may have an Allocation that consumes all of a Bare Metal Node’s Inventory
If we now look at the resource provider inventory record for a bare metal node, it might look like this:
{
"inventories": {
"CUSTOM_GOLD": {
"allocation_ratio": 1.0,
"max_unit": 1,
"min_unit": 1,
"reserved": 0,
"step_size": 1,
"total": 1
}
},
"resource_provider_generation": 1
}
We have just one unit of one resource class, in this case CUSTOM_GOLD. The resource class comes from the resource_class field of the node in Ironic, upper-cased, and with a prefix of CUSTOM_ to denote that it is a custom resource class as opposed to a standard one like VCPU.
What sort of Nova flavor would be required to schedule to this node?
openstack flavor show bare-metal-gold -f json \
-c name -c ram -c properties -c vcpus -c disk
{
"name": "bare-metal-gold",
"vcpus": 4,
"ram": 4096,
"disk": 1024,
"properties": "resources:CUSTOM_GOLD='1',
resources:DISK_GB='0',
resources:MEMORY_MB='0',
resources:VCPU='0'"
}
Note that the standard fields (vcpus etc.) may be specified for informational purposes, but should be zeroed out using properties as shown.
Traits
So far we have covered scheduling based on quantitative resources. Placement uses traits to model qualitative resources. These are associated with resource providers. For example, we might query GET /resource_providers/{uuid}/traits for a resource provider that has an FPGA to find some information about the class of the FPGA device.
{
"resource_provider_generation": 1,
"traits": [
"CUSTOM_HW_FPGA_CLASS1",
"CUSTOM_HW_FPGA_CLASS3"
]
}
Ironic nodes can have traits assigned to them, in addition to their resource class: GET /nodes/{uuid}?fields=name,resource_class,traits:
{
"Name": "gold-node-1",
"Resource Class": "GOLD",
"Traits": [
"CUSTOM_RAID0",
"CUSTOM_RAID1",
]
}
Similarly to quantitative scheduling, traits may be specified via a flavor when creating an instance.
openstack flavor show bare-metal-gold -f json -c name -c properties
{
"name": "bare-metal-gold",
"properties": "resources:CUSTOM_GOLD='1',
resources:DISK_GB='0',
resources:MEMORY_MB='0',
resources:VCPU='0',
trait:CUSTOM_RAID0='required'"
}
This flavor will select bare metal nodes with a resource_class of CUSTOM_GOLD, and a list of traits including CUSTOM_RAID0.
To allow ironic to take action based upon the requested traits, the list of required traits are stored in the Ironic node object under the instance_info field.
Ironic deploy steps
The Ironic deploy steps framework was added in the Rocky cycle as a first step towards making the deployment process more flexible. It is based on the clean step model described earlier, and allows drivers to define steps available to be executed during deployment. Here is the simplified state diagram we saw earlier, this time highlighting the deploying state in which deploy steps are executed.
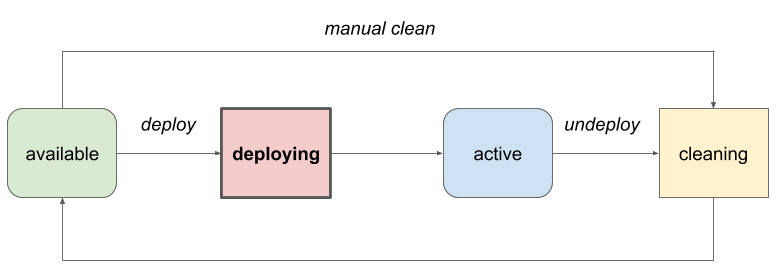
Each deploy step has:
- interface: One of deploy, power, management, bios, raid
- step: Method (function) name on the driver interface
- args: Dictionary of keyword arguments
- priority: Order of execution (higher runs earlier)
Notice that this is the same as for clean steps.
The mega step
In the Rocky cycle, the majority of the deployment process was moved to a single step called deploy on the deploy interface with a priority of 100. This step roughly does the following:
- power on the node to boot up the agent
- wait for the agent to boot
- write the image to disk
- power off
- unplug from provisioning networks
- plug tenant networks
- set boot mode
- power on
Drivers can currently add steps before or after this step. The plan is to split this into multiple core steps for more granular control over the deployment process.
Limitations
Deploy steps are static for a given set of driver interfaces, and are currently all out of band - it is not possible to execute steps on the deployment agent. Finally, the mega step limits ordering of the steps.
Ironic deploy templates
The Ironic deploy templates API was added in the Stein cycle and allows deployment templates to be registered which have:
- a name, which must be a valid trait
- a list of deployment steps
For example, a deploy template could be registered via POST /v1/deploy_templates:
{
"name": "CUSTOM_HYPERTHREADING_ON",
"steps": [
{
"interface": "bios",
"step": "apply_configuration",
"args": {
"settings": [
{
"name": "LogicalProc",
"value": "Enabled"
}
]
},
"priority": 150
}
]
}
This template has a name of CUSTOM_HYPERTHREADING_ON (which is also a valid trait name), and references a deploy step on the bios interface that sets the LogicalProc BIOS setting to Enabled in order to enable Hyperthreading on a node.
Tomorrow’s RAID
In the Stein release we have the deploy templates and steps frameworks, but lack drivers with deploy step implementations to make this useful. As part of the demo for the Bespoke Bare Metal talk, we built and demoed a proof of concept deploy step for configuring RAID during deployment on Dell machines. This code has been polished and is working its way upstream at the time of writing, and has also influenced deploy steps for the HP iLO driver. Thanks to Shivanand Tendulker for extracting and polishing some of the code from the PoC.
We now have an apply_configuration deploy step available on the RAID interface which accepts RAID configuration as an argument, to avoid the separate API call required in cleaning.
The first pass at implementing this in the iDRAC driver took over 30 minutes to complete deployment. This was streamlined to just over 10 minutes by combining deletion and creation of virtual disks into a single deploy step, and avoiding an unnecessary reboot.
End to end flow
Now we know what a deploy template looks like, how are they used?
First of all, the cloud operator creates deploy templates via the Ironic API to execute deploy steps for allowed actions. In this example, we have a deploy template used to create a 42GB RAID1 virtual disk.
cat << EOF > raid1-steps.json
[
{
"interface": "raid",
"step": "apply_configuration",
"args": {
"raid_config": {
"logical_disks": [
{
"raid_level": "1",
"size_gb": 42,
"is_root_volume": true
}
]
}
},
"priority": 150
}
]
EOF
openstack baremetal deploy template create \
CUSTOM_RAID1 \
--steps raid1-steps.json
Next, the operator creates Nova flavors or Glance images with required traits that reference the names of deploy templates.
openstack flavor create raid1 \
--property resources:VCPU=0 \
--property resources:MEMORY_MB=0 \
--property resources:DISK_GB=0 \
--property resources:CUSTOM_COMPUTE=1 \
--property trait:CUSTOM_RAID1=required
Finally, a user creates a bare metal instance using one of these flavors that is accessible to them.
openstack server create \
--name test \
--flavor raid1 \
--image centos7 \
--network mynet \
--key-name mykey
What happens? A bare metal node is scheduled by Nova which has all of the required traits from the flavor and/or image. Those traits are then used by Ironic to find deploy templates with matching names, and the deploy steps from those templates are executed in addition to the core step, in an order determined by their priorities. In this case, the RAID apply_configuration deploy step runs before the core step because it has a higher priority.
Future Challenges
There is still work to be done to improve the flexibility of bare metal deployment. We need to split out the mega step. We need to support executing steps in the agent running on the node, which would enable deployment-time use of the software RAID support recently developed by Arne Wiebalck from CERN.
Drivers need to expose more deploy steps for BIOS, RAID and other functions. We should agree on how to handle executing a step multiple times, and all the tricky corner cases involved.
We have discussed the Nova use case here, but we could also make use of deploy steps in standalone mode, by passing a list of steps to execute to the Ironic provision API call, similar to manual cleaning. There is also a spec proposed by Madhuri Kumari which would allow reconfiguring active nodes to do things like tweak BIOS settings without requiring redeployment.
Thanks to everyone who has been involved in designing, developing and reviewing the series of features in Nova and Ironic that got us this far. In particular John Garbutt who proposed the specs for deploy steps and deploy templates, and Ruby Loo who implemented the deploy steps framework.