For optimal reading, please switch to desktop mode.
This analysis was performed using Kata containers version 1.6.2, the latest at the time of writing.
After attending a Kata Containers workshop at OpenInfra Days 2019 in London, we were impressed by their start-up time, only marginally slower compared to ordinary runC containers in a Kubernetes cluster. We were naturally curious about their disk I/O bound performance and whether they also live up to the speed claims. In this article we explore this subject with a view to understanding the trade offs of using this technology in environments where I/O bound performance and security are both critical requirements.
What are Kata containers?
Kata containers are lightweight VMs designed to integrate seamlessly with container orchestration software like Docker and Kubernetes. One envisaged use case is running untrusted workloads, exploiting the additional isolation gained by not sharing the Operating System kernel with the host. However, the unquestioning assumption that using a guest kernel leads to additional security is challenged in a recent survey of virtual machines and containers. Kata has roots in Intel Clear Containers and Hyper runV technology. They are also often mentioned alongside gVisor, which aims to solve a similar problem by filtering and redirecting system calls to a separate user space kernel. As a result gVisor suffers from runtime performance penalties. Further discussion on gVisor is out of scope in this blog.
Configuring Kubernetes for Kata
Kata containers are OCI conformant which means that a Container Runtime Interface (CRI) that supports external runtime classes can use Kata to run workloads. Examples of these CRIs currently include CRI-O and containerd which both use runC by default, but this can be swapped for the kata-qemu runtime. From Kubernetes 1.14+ onwards, the RuntimeClass feature flag has been promoted to beta, therefore enabled by default. Consequently the setup is relatively straightforward.
At present Kata supports qemu and firecracker hypervisor backends, but the support for the latter is considered preliminary, especially a lack of host to guest file sharing. This leaves us with kata-qemu as the current option, in which virtio-9p provides the basic shared filesystem functionalities critical for this analysis (the test path is a network filesystem mounted on the host).
This example Gist shows how to swap runC for Kata runtime in a Minikube cluster. Note that at the time of writing, Kata containers have additional host requirements:
- Kata will only run on a machine configured to support nested virtualisation.
- Kata requires at least a Westmere processor architecture.
Without these prerequisites Kata startup will fail silently (we learnt this the hard way).
For this analysis a baremetal Kubernetes cluster was deployed, using OpenStack Heat to provision the machines via our appliances playbooks and Kubespray to configure them as a Kubernetes cluster. Kubespray supports specification of container runtimes other than Docker, e.g. CRI-O and containerd, which is required to support the Kata runtime.
Designing the I/O Performance Study
To benchmark the I/O performance Kata containers, we present equivalent scenarios in bare metal and runC container cases to draw comparison. In all cases, we use fio (version 3.1) as the I/O benchmarking tool invoked as follows where $SCRATCH_DIR is the path to our BeeGFS (described in more detail later in this section) network storage mounted on the host:
fio fio_jobfile.fio --fallocate=none --runtime=30 --directory=$SCRATCH_DIR --output-format=json+ --blocksize=65536 --output=65536.json
The fio_jobfile.fio file referenced above reads as follows:
[global]
; Parameters common to all test environments
; Ensure that jobs run for a specified time limit, not I/O quantity
time_based=1
; To model application load at greater scale, each test client will maintain
; a number of concurrent I/Os.
ioengine=libaio
iodepth=8
; Note: these two settings are mutually exclusive
; (and may not apply for Windows test clients)
direct=1
buffered=0
; Set a number of workers on this client
thread=0
numjobs=4
group_reporting=1
; Each file for each job thread is this size
filesize=32g
size=32g
filename_format=$jobnum.dat
[fio-job]
; FIO_RW is read, write, randread or randwrite
rw=${FIO_RW}
In order to understand how the performance scales with the number of I/O bound clients, we look at 1, 8 and 64 clients. While the single client is instantiated on a single instance, for the cases with 8 and 64 clients, they run in parallel across across 2 worker instances, with 4 and 32 clients per bare metal instance respectively. Additionally, each fio client instantiates 4 threads which randomly and sequentially read and write a 32G file per thread, depending on the scenario.
All scenarios are configured with a block size of 64K. It is worth noting that the direct=true flag has not been supplied to fio for these tests as it is not representative of a typical use case.
The test infrastructure is set up in an optimal configuration for data-intensive analytics. The storage backend which consists of NVMe devices is implemented with BeeGFS, a parallel file system for which we have an Ansible Galaxy role and have previously written about. The network connectivity between the test instances and BeeGFS storage platform uses RDMA over a 100G Infiniband fabric.
| Scenario | Number of clients | Disk I/O pattern |
|---|---|---|
| bare metal | 1 | sequential read |
| runC containers | 8 | random read |
| Kata containers | 64 | sequential write |
| random write |
The parameter space explored for the I/O performance study covers 36 combinations of scenarios, number of clients and disk I/O pattern.
Results
Disk I/O Bandwidth
In these results we plot the aggregate bandwidth across all clients, demonstrating the scale-up bandwidth achievable by a single client and the scale-out throughput achieved across many clients.
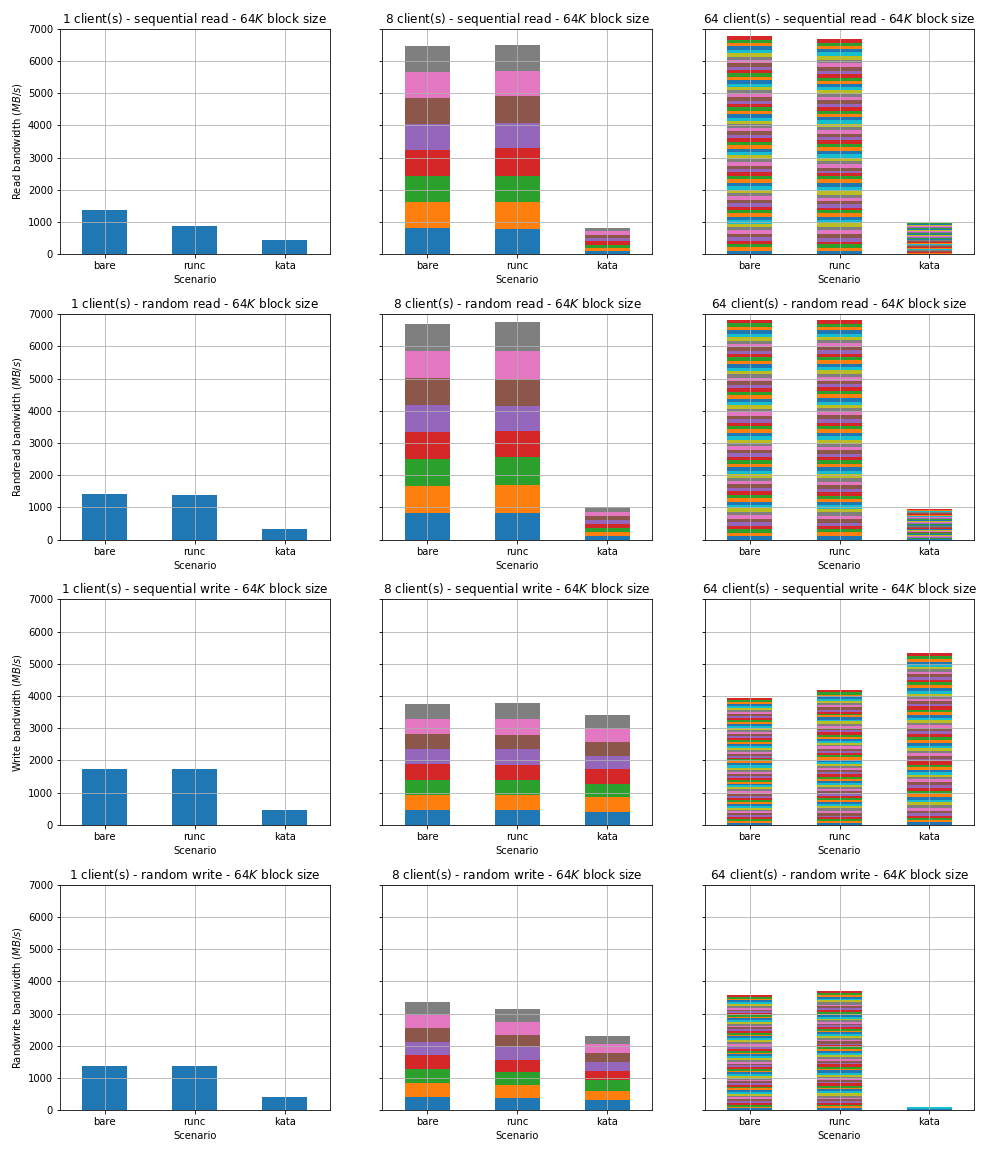
Comparison of disk I/O bandwidth between between bare metal, runC and Kata. In all cases, the bandwidth achieved with runC containers is slightly below bare metal. However, Kata containers generally fare much worse, achieving around 15% of the bare metal read bandwidth and a much smaller proportion of random write bandwidth when there are 64 clients. The only exception is the sequential write case using 64 clients, where Kata containers appear to outperform baremetal scenario by approximately 25%.
Commit Latency Cumulative Distribution Function (CDF)
In latency-sensitive workloads, I/O latency can dominate. I/O operation commit latency is plotted on a logarithmic scale, to fit a very broad range of data points.
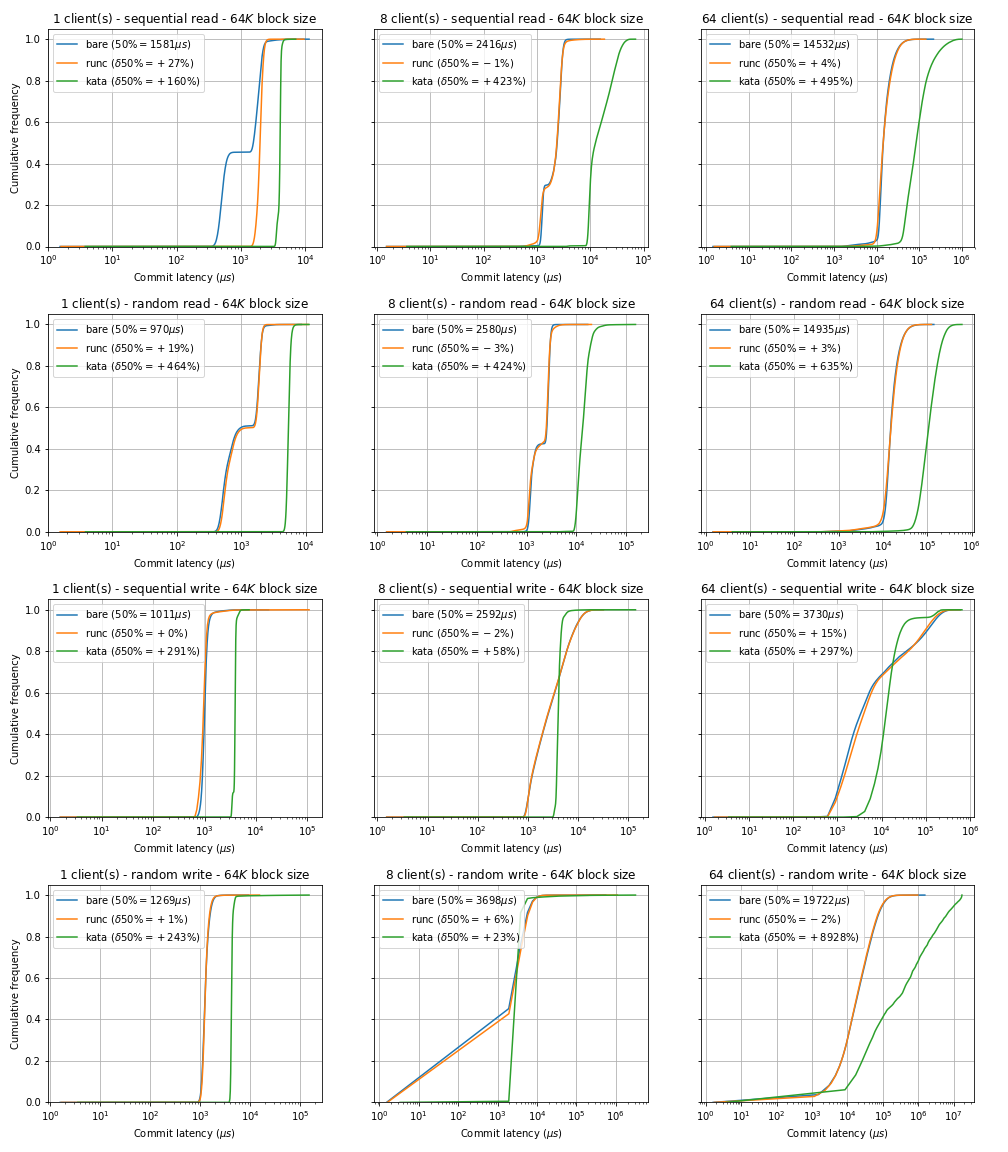
Comparison of commit latency CDF between bare metal, runC and Kata container environments for 1, 8 and 64 clients respectively. There is a small discrepancy between running fio jobs in bare metal compared to running them as runC containers. However, comparing bare metal to Kata containers, the overhead is significant in all cases.
| Number of clients > | 1 | 8 | 64 | ||||
|---|---|---|---|---|---|---|---|
| Mode | Scenario | 50% | 99% | 50% | 99% | 50% | 99% |
| sequential read | bare | 1581 | 2670 | 2416 | 3378 | 14532 | 47095 |
| runC | 2007 | 2506 | 2391 | 3907 | 15062 | 46022 | |
| Kata | 4112 | 4620 | 12648 | 46464 | 86409 | 563806 | |
| random read | bare | 970 | 2342 | 2580 | 3305 | 14935 | 43884 |
| runC | 1155 | 2277 | 2506 | 3856 | 15378 | 42229 | |
| Kata | 5472 | 6586 | 13517 | 31080 | 109805 | 314277 | |
| sequential write | bare | 1011 | 1728 | 2592 | 15023 | 3730 | 258834 |
| runC | 1011 | 1990 | 2547 | 14892 | 4308 | 233832 | |
| Kata | 3948 | 4882 | 4102 | 6160 | 14821 | 190742 | |
| random write | bare | 1269 | 2023 | 3698 | 11616 | 19722 | 159285 |
| runC | 1286 | 1957 | 3928 | 11796 | 19374 | 151756 | |
| Kata | 4358 | 5275 | 4566 | 14254 | 1780559 | 15343845 | |
Table summarising the 50% and the 99% commit latencies (in μs) corresponding to the figure shown earlier.
Looking Ahead
In an I/O intensive scenario such as this one, Kata containers do not yet match the performance of conventional containers.
It is clear from the results that there are significant trade offs to consider when choosing between bare metal, runC and Kata containers. While runC containers provide valuable abstractions for most use cases, they still leave the host kernel vulnerable to exploit with the system call interface as attack surface. Kata containers provide hardware-supported isolation but currently there is significant performance overhead, especially for disk I/O bound operations.
Kata's development roadmap and pace of evolution provide substantial grounds for optimism. The Kata team are aware of the performance drawbacks of using virtio-9p as the storage driver for sharing paths between host and guest VMs.
Kata version 1.7 (due on 15 May 2019) is expected to ship with experimental support for virtio-fs which is expected to improve I/O performance issues. Preliminary results look encouraging, with other published benchmarks reporting the virtio-fs driver demonstrating 2x to 8x disk I/O bandwidth improvement over virtio-9p. We will repeat our analysis when the new capabilities become available.
In the meantime, if you would like to get in touch we would love to hear from you, especifically if there is a specific configuration which we may not have considered. Reach out to us on Bluesky or directly via our contact page.