For optimal reading, please switch to desktop mode.
StackHPC contributed this research to a challenging project with our clients at G Research, technology leaders in the field of high-performance cloud.
One aspect of open infrastructure that makes it an exciting field to work in is that it is a continually changing landscape. This is particularly true in the arena of high performance networking.
Open Infrastructure
The concept of Open Infrastructure may not be familiar to all. It seeks to replicate the open source revolution in compute, exemplified by Linux, for the distributed management frameworks of cloud computing. At its core is OpenStack, the cloud operating system that has grown to become one of the most popular open source projects in the world.
Kayobe is an open source project for deploying and operating OpenStack in a model that packages all OpenStack’s components as containerised microservices and orchestrates the logic of their deployment, reconfiguration and life cycle using Ansible.
High Performance Networking
In cloud environments, Single-Root IO Virtualisation (SR-IOV) is still the way to achieve highest performance in virtualised networking, and remains popular for telcos, high-performance computing (HPC) and other network-intensive use cases. RDMA (the HPC-derived network technology for bypassing kernel network stacks) in VMs is only possible through use of SR-IOV.
The concept of SR-IOV is that the hardware resources of a physical NIC (the physical function, or PF) are presented as many additional virtual functions (or VFs). The VFs are treated like separable devices and can be passed-through to VMs to provide them with direct access to networking hardware.
Historically, this performance has been counter-balanced by limitations on its use:
- SR-IOV configurations usually bypass the security groups that implement firewall protection for VMs.
- SR-IOV used to prevent key operational features such as live migration (we will be following up on the new live migration capabilities added in the Train release and the consequences of it in a follow-up article).
- SR-IOV configurations can be complex to set up.
- VMs require hardware drivers to enable use of the SR-IOV interfaces.
- SR-IOV lacked fault tolerance. In standard configurations SR-IOV is associated with a single physical network interface.
The lack of support for high-availability in networking can be addressed - with the right network hardware.
Mellanox VF-LAG: Fault-tolerance for SR-IOV
In a resilient design for a virtualised data centre, hypervisors use bonded NICs to provide network access for control plane data services and workloads running in VMs. This design provides active-active use of a pair of high-speed network interfaces, but would normally exclude the most demanding network-intensive use cases.
Mellanox NICs have a feature, VF-LAG, which claims to enable SR-IOV to work in configurations where the ports of a 2-port NIC are bonded together.
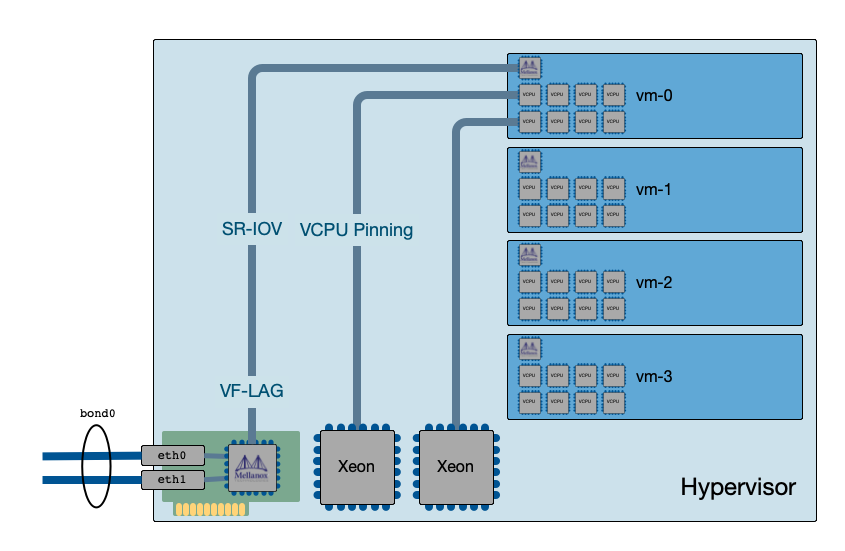
VMs configured using VF-LAG, combining SR-IOV and bonded physical interfaces
In NICs that support it, VF-LAG uses the same technology underpinning ASAP2 OVS hardware offloading; much of the process for creation of VF-LAG configurations is common with ASAP2.
System Requirements
- VF-LAG requires Mellanox ConnectX-5 (or later) NICs.
- VF-LAG only works for two ports on the same physical NIC. It cannot be used for LAGs created using multiple NICs.
- Open vSwitch version 2.12 or later (the Train release of Kolla shipped with Open vSwitch 2.12).
The Process for VF-LAG Creation
A standard procedure can be applied for SR-IOV, but for VF-LAG support some changes are required due to specific ordering restrictions with VF-LAG hardware initialisation.
System Configuration
NIC Firmware Configuration
Both ports must be put into Ethernet mode. SR-IOV must be enbled, and the limit on the number of Virtual Functions must be set to the maximum number of VF-LAG VFs planned during hypervisor operation.
To set firmware parameters, the mft package is required from Mellanox OFED.
When OFED packages are installed, take care not to enable the Mellanox interface manager or openibd service. These will interfere with device initialisation ordering.
Use of Mellanox Firmware Tools is described on a Mellanox community support page here.
mst start
mst status
# Set Ethernet mode on both ports
mlxconfig -d /dev/mst/<device_name> set LINK_TYPE_P1=2 LINK_TYPE_P2=2
# Enable SRIOV and set a maximum number of VFs on each port (here, 8 VFs)
mlxconfig -d /dev/mst/<device_name> set SRIOV_EN=1 NUM_OF_VFS=8
reboot
Once applied, these settings are persistent and should not require further changes.
BIOS Configuration
BIOS support is required for SR-IOV and hardware I/O virtualisation. On Intel systems this may refer to VT-d. No further configuration is required to support VF-LAG.
Kernel Boot Parameters
Kernel boot parameters are required to support direct access to SR-IOV hardware using I/O virtualisation.
For Intel systems these are:
intel_iommu=on iommu=pt
Similarly for AMD systems:
amd_iommu=on iommu=pt
(For performance-optimised configurations you might also want to set kernel boot parameters for static huge pages and processor C-states).
Open vSwitch Configuration
Open vSwitch is configured to enable hardware offload of the OVS data plane. This configuration must be applied to every hypervisor using VF-LAG, and is applied to the openvswitch_vswitchd container.
Open vSwitch must be at version 2.12 or later (available as standard from RDO package archives and Kolla-Ansible Train release, or later).
# Enable hardware offloads:
docker exec openvswitch_vswitchd ovs-vsctl set Open_vSwitch . other_config:hw-offload=true
# Verify hardware offloads have been enabled:
docker exec openvswitch_vswitchd ovs-vsctl get Open_vSwitch . other_config:hw-offload
"true"
OpenStack Configuration
OpenStack Nova and Neutron must be configured for SR-IOV as usual. See the previous blog post for further details on how this is done.
OpenStack networking must be configured without a Linuxbridge directly attached to the bond0 interface. In standard configurations this can mean that only tagged VLANs (and not the native untagged VLAN) can be used with the bond0 device.
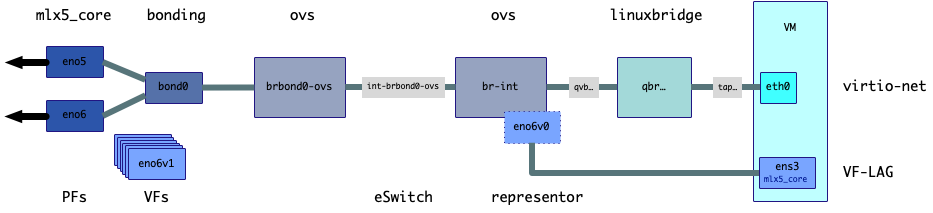
Kayobe hypervisor virtual networking configuration that supports hardware offloading
Boot-time Initialisation
The divergence from the standard bootup procedures for SR-IOV starts here.
Early Setup: Creation of SR-IOV VFs
VF-LAG hardware and driver initialisation must be applied in a strict order with regard to other network subsystem initialisations. Early hardware and driver configuration must be performed before the interfaces are bonded together.
Systemd dependencies are used to ensure that VF-LAG initialisation is applied after device driver initialisation and before starting the rest of networking initialisation.
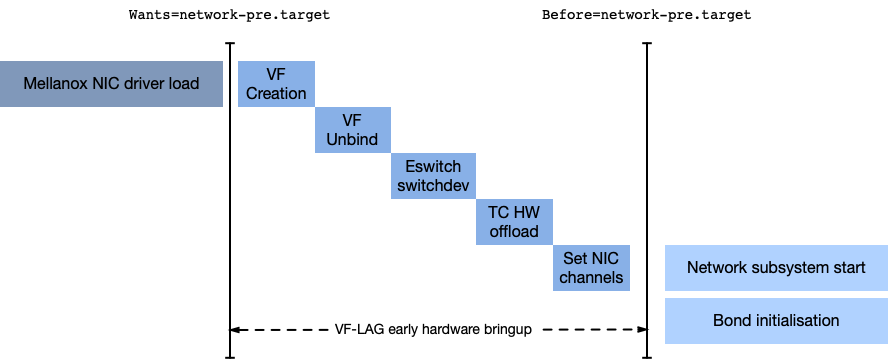
Systemd is used to ensure VF-LAG bootup ordering dependencies are met.
As a systemd unit, define the dependencies as follows to ensure VF-LAG setup happens after drivers are loaded but before networking initiasation commences (here we use the physical NIC names ens3f0 and ens3f1):
Requires=sys-subsystem-net-devices-ens3f0.device
After=sys-subsystem-net-devices-ens3f0.device
Requires=sys-subsystem-net-devices-ens3f1.device
After=sys-subsystem-net-devices-ens3f1.device
Before=network-pre.target
Requires=network-pre.target
Virtual functions (VFs) are created on both physical NICs in the bond.
For pass-through to VMs, the VFs are unbound from the Ethernet driver in the host kernel. VF configuration is managed at "arms length" through use of a representor device, created as a placeholder for referring to the VF without taking ownership of it.
This script implements the required process and ordering:
#!/bin/bash
[ -f /etc/sysconfig/sriov ] && source /etc/sysconfig/sriov
# Defaults
# The network devices on which we create VFs.
SRIOV_PFS=${SRIOV_PFS:-"ens3f0 ens3f1"}
# The number of VFs to create on each PF
SRIOV_VF_COUNT=${SRIOV_VF_COUNT:-8}
# The number of combined channels to enable on each PF
SRIOV_PF_CHANNELS=${SRIOV_PF_CHANNELS:-63}
# The number of combined channels to enable on each representor
SRIOV_VF_CHANNELS=${SRIOV_VF_CHANNELS:-18}
function sriov_vf_create
{
PF_NIC=$1
VF_COUNT=$2
cd /sys/class/net/$PF_NIC/device
PF_PCI=pci/$(basename $(realpath $PWD))
logger -t mlnx-vflag-early "Creating $VF_COUNT VFs for $PF_NIC ($PF_PCI)"
echo $VF_COUNT > sriov_numvfs
for i in $(readlink virtfn*)
do
logger -t mlnx-vflag-early "Unbinding $(basename $i)"
echo $(basename $i) > /sys/bus/pci/drivers/mlx5_core/unbind
done
# Put the NIC eSwitch into devlink mode
devlink dev eswitch set $PF_PCI mode switchdev
logger -t mlnx-vflag-early "After enabling switchdev: $(devlink dev eswitch show $PF_PCI)"
}
function enable_tc_offload
{
PF_NIC=$1
TC_OFFLOAD=$(ethtool -k $PF_NIC | awk '{print $2}')
if [[ "$TC_OFFLOAD" != "on" ]]
then
logger -t mlnx-vflag-early "Enabling HW TC offload for $PF_NIC"
ethtool -K $PF_NIC hw-tc-offload on
fi
}
function hwrep_ethtool
{
# There isn't an obvious way to connect a representor port
# back to the PF or VF, so apply tuning to all representor ports
# served by the mlx5e_rep driver.
hwrep_devs=$(cd /sys/devices/virtual/net; for i in *
do
ethtool -i $i 2> /dev/null |
awk -v dev=$i '$1=="driver:" && $2=="mlx5e_rep" {print dev}'
done)
for i in $hwrep_devs
do
logger -t mlnx-vflag-early "Tuning receive channels for representor $i"
ethtool -L $i combined $SRIOV_VF_CHANNELS
# Enable hardware TC offload for each representor device
enable_tc_offload $i
done
}
for PF in $SRIOV_PFS
do
# Validate that the NIC exists as a network device
if [[ ! -d /sys/class/net/$PF ]]
then
logger -t mlnx-vflag-early "NIC $PF not found, aborting"
echo "mlnx-vflag-early: NIC $PF not found" >&2
exit -1
fi
# Validate that the NIC is not already up and active in a bond
# It appears this could be fatal.
dev_flags=$(ip link show dev $PF | grep -o '<.*>')
grep -q '\<SLAVE\>' <<< $dev_flags
if [[ $? -eq 0 ]]
then
logger -t mlnx-vflag-early "NIC $PF already part of a bond, aborting"
echo "mlnx-vflag-early: NIC $PF already part of a bond" >&2
exit -1
fi
sriov_vf_create $PF $SRIOV_VF_COUNT
enable_tc_offload $PF
# Raise the receive channels configured for this PF, if too low
logger -t mlnx-vflag-early "Tuning receive channels for PF $PF"
ethtool -L $PF combined $SRIOV_PF_CHANNELS
done
hwrep_ethtool
Late Boot: Binding VFs back
A second Systemd unit is required to run later in the boot process: after networking setup is complete but before the containerised OpenStack services are started.
This can be achieved with the following dependencies:
Wants=network-online.target
After=network-online.target
Before=docker.service
At this point, the VFs are rebound to the Mellanox network driver. The following script serves as an example:
#!/bin/bash
[ -f /etc/sysconfig/sriov ] && source /etc/sysconfig/sriov
function sriov_vf_bind
{
PF_NIC=$1
if [[ ! -d /sys/class/net/$PF_NIC ]]
then
logger -t mlnx-vflag-final "NIC $PF_NIC not found, aborting"
echo "mlnx-vflag-final: NIC $PF_NIC not found" >&2
exit -1
fi
# Validate that the NIC is configured to be part of a bond.
dev_flags=$(ip link show dev $PF_NIC | grep -o '<.*>')
grep -q '\<SLAVE\>' <<< $dev_flags
if [[ $? -ne 0 ]]
then
logger -t mlnx-vflag-final "NIC $PF_NIC not part of a bond, VF-LAG abort"
echo "mlnx-vflag-final: NIC $PF_NIC not part of a bond, VF-LAG abort" >&2
exit -1
fi
# It appears we need to rebind the VFs to NIC devices, and then
# attach the NIC devices to the OVS bridge to which our bond is attached.
cd /sys/class/net/$PF_NIC/device
PF_PCI=pci/$(basename $(realpath $PWD))
for i in $(readlink virtfn*)
do
logger -t mlnx-vflag-final "Binding $(basename $i)"
echo $(basename $i) > /sys/bus/pci/drivers/mlx5_core/bind
done
}
# The network devices on which we create VFs.
SRIOV_PFS=${SRIOV_PFS:-"ens3f0 ens3f1"}
for PF in $SRIOV_PFS
do
sriov_vf_bind $PF
done
Performance Tuning
High-performance networking will also benefit from configuring multiple receive channels. These should be configured for the PF and also the representors. Check the current setting using ethtool -l and adjust if necessary:
ethtool -L ens3f0 combined 18
Mellanox maintains a comprehensive performance tuning guide for their NICs.
Using VF-LAG interfaces in VMs
In common with SR-IOV and OVS hardware-offloaded ports, ports using VF-LAG and OVS hardware offloading must be created separately and with custom parameters:
openstack port create --network $net_name --vnic-type=direct --binding-profile '{"capabilities": ["switchdev"]}' $hostname-vflag
A VM instance can be created specifying the VF-LAG port. In this example, it is one of two ports connected to the VM:
openstack server create --key-name $keypair --image $image --flavor $flavor --nic net-id=$tenant_net --nic port-id=$vflag_port_id $hostname
The VM image should include Mellanox NIC kernel drivers to use the VF LAG interface.
Troubleshooting: Is it Working?
Check that the Mellanox Ethernet driver is managing the LAG correctly:
# dmesg | grep 'mlx5.*lag'
[ 44.064025] mlx5_core 0000:37:00.0: lag map port 1:2 port 2:2
[ 44.196781] mlx5_core 0000:37:00.0: modify lag map port 1:1 port 2:1
[ 46.491380] mlx5_core 0000:37:00.0: modify lag map port 1:2 port 2:2
[ 46.591272] mlx5_core 0000:37:00.0: modify lag map port 1:1 port 2:2
Check that the VFs have been created during bootup:
# lspci | grep Mellanox
5d:00.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx]
5d:00.1 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx]
5d:00.2 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:00.3 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:00.4 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:00.5 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:00.6 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:00.7 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.1 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.2 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.3 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.4 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.5 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.6 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:01.7 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:02.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
5d:02.1 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx Virtual Function]
Data about VFs for a given NIC (PF) can also be retrieved using ip link (here for ens3f0):
# ip link show dev ens3f0
18: ens3f0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond0 state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:b4:30:8a brd ff:ff:ff:ff:ff:ff
vf 0 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
vf 1 link/ether 3a:c0:c7:a5:ab:b2 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
vf 2 link/ether 82:f5:8f:52:dc:2f brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
vf 3 link/ether 3a:62:76:ef:69:d3 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
vf 4 link/ether da:07:4c:3d:29:7a brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
vf 5 link/ether 7e:9b:4c:98:3b:ff brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
vf 6 link/ether 42:28:d1:6a:0d:5d brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
vf 7 link/ether 86:d2:c8:a4:1b:c6 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state disable, trust off, query_rss off
The configured number of VFs should also be available via sysfs (shown here for NIC eno5):
cat /sys/class/net/eno5/device/sriov_numvfs
8
Check that the Mellanox NIC eSwitch has been put into switchdev mode, not legacy mode (use the PCI bus address for the NIC from lspci, here 37:00.0):
# devlink dev eswitch show pci/0000:37:00.0
pci/0000:37:00.0: mode switchdev inline-mode none encap enable
Check that tc hardware offloads are enabled on the physical NICs and also the representor ports (shown here for a NIC ens3f0 and a representor eth0):
# ethtool -k ens3f0 | grep hw-tc-offload
hw-tc-offload: on
# ethtool -k eth0 | grep hw-tc-offload
hw-tc-offload: on
Check that Open vSwitch is at version 2.12 or later:
# docker exec openvswitch_vswitchd ovs-vsctl --version
ovs-vsctl (Open vSwitch) 2.12.0
DB Schema 8.0.0
Check that Open vSwitch has hardware offloads enabled:
# docker exec openvswitch_vswitchd ovs-vsctl get Open_vSwitch . other_config:hw-offload
"true"
Once a VM has been created and has network activity on an SR-IOV interface, check for hardware-offloaded flows in Open vSwitch. Look for offloaded flows coming in on both bond0 and on the SR-IOV VF:
# docker exec openvswitch_vswitchd ovs-appctl dpctl/dump-flows --names type=offloaded
in_port(bond0),eth(src=98:5d:82:b5:d2:e5,dst=fa:16:3e:44:44:71),eth_type(0x8100),vlan(vid=540,pcp=0),encap(eth_type(0x0800),ipv4(frag=no)), packets:29, bytes:2842, used:0.550s, actions:pop_vlan,eth9
in_port(eth9),eth(src=fa:16:3e:44:44:71,dst=00:1c:73:00:00:99),eth_type(0x0800),ipv4(frag=no), packets:29, bytes:2958, used:0.550s, actions:push_vlan(vid=540,pcp=0),bond0
Watch out for kernel errors logged of this form as a sign that offloading is not applying successfully:
2020-03-19T11:42:17.028Z|00001|dpif_netlink(handler223)|ERR|failed to offload flow: Operation not supported: bond0
Performance
The performance achieved rewards the effort. VMs connected with VF-LAG are close to saturating the hardware bus for PCIe gen 3 (just under 100Gb/s). Message latencies, measured using standard HPC benchmarking tools, are quantifiable but small.
Looking ahead, we'll be building on this capability in follow-up blog posts.
References
Documentation on VF-LAG is hard to find (hence this post):
- A Mellanox community post with step-by-step guidance for a manual setup of VF-LAG.
However, ASAP2 integration with OpenStack is well covered in some online sources:
- Melanox provide a useful page for debug of ASAP2, which is similar in requirements this use case with VF-LAG.
- OpenStack-Ansible has a page on configuring for ASAP2.
- Another useful page on configuring for OVS hardware offloads from Neutron
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky or directly via our contact page.