For optimal reading, please switch to desktop mode.
Background
When I joined StackHPC for the summer, Mark gave me a problem description. Testing OpenStack Ironic tends to be tough, due to the difficulty of finding and provisioning bare metal hardware for the purpose. The normal solution to this is to set up one or more virtual machines to act as pseudo-bare metal servers to simulate a cluster. Automation of this task already exists in Bifrost's test scripts1, TripleO's quickstart2, Ironic's own DevStack script3, and possibly others too. However, none of these has become a de facto tool for virtual cluster deployment, be it due to lack of extensibility, tight coupling with their respective environment, or an architecture centred around monolithic shell scripts.

...enter Tenks!
Tenks4 is a new tool designed to solve this problem.
 |
|---|
| Source: xkcd 927 5 |
Written mostly in Ansible with custom Python plugins where necessary, it is designed to be a general virtual cluster orchestration utility. As well as allowing a developer to spin up a test cluster with minimal configuration, Mark explained that neither the Kolla6 nor the Kayobe project7 performs testing of Ironic in any of its continuous integration jobs; this is another key use case which Tenks should assist with.
Implementation
Key Features
After some discussion and drafting of an Ironic feature specification8, the scope was broken down into a few key components, and a set of desired capabilities was created. Some of the features that have been implemented include:
-
Multi-hypervisor support. While the commonest use case may well be all-in-one deployment (when all cluster nodes are hosted on the same machine from which Tenks is executed: localhost), it was deemed important for Tenks to allow the use of multiple different hypervisors, each of which hosting a subset of the cluster nodes (localhost optionally also performing this role).
This feature was implemented almost "for free", thanks to Ansible's multi-host nature9. Different Ansible groups are defined to represent the different roles within Tenks, and the user creates an inventory file to add hosts to each group as they please.
-
Extensibility. Tenks was designed with a set of default assumptions. These include the assumption that the user will want to employ the Libvirt/QEMU/KVM stack to provide virtualisation on the hypervisors and Virtual BMC10 to provide a virtual platform management interface using IPMI; it is also assumed that the user will have provisioned the physical network infrastructure between the hypervisors.
However, these assumptions do not impact the extensibility of Tenks. The tool is written as a set of Ansible playbooks, each of which delegates different tasks to different hosts. If, in future, there is a use case for OpenStack to be added as a provider in place of the Libvirt stack (as the sushy-tools emulator11, for example, already allows), the existing plays need not be modified. The new provider can be added as a sub-group of the existing Ansible hypervisors group: any existing Libvirt-specific tasks will automatically be omitted, and new tasks can be added for the new group.
-
Tear-down and reconfiguration. Whether used as an ephemeral cluster for a CI job or for a developer's test environment, a deployed Tenks cluster will need to be cleaned up afterwards. A developer may also wish to reconfigure their cluster to add or remove nodes, without affecting the existing nodes.
Tear-down was reasonably easy to implement due to the modular nature of Tenks' tasks. To a large extent, tear-down involves running the deployment playbooks "in reverse". The Ansible convention of having a
statevariable with valuespresentandabsentmeans that minimal duplication of logic was required to do this.Reconfiguration required a little more thought, but this too was implemented without too much disruption to the core playbooks. The scheduling of nodes to hypervisors is performed by a custom Ansible action plugin, which is where most of the reconfiguration logic lies. The state of the existing cluster (if any) is preserved in a YAML file, and this is compared to the cluster configuration that was given to Tenks. The scheduling plugin decides which existing nodes should be purged, and how many new nodes need to be provisioned. It eventually outputs an updated cluster state which is saved in the YAML file, then the rest of Tenks runs as normal from this configuration.
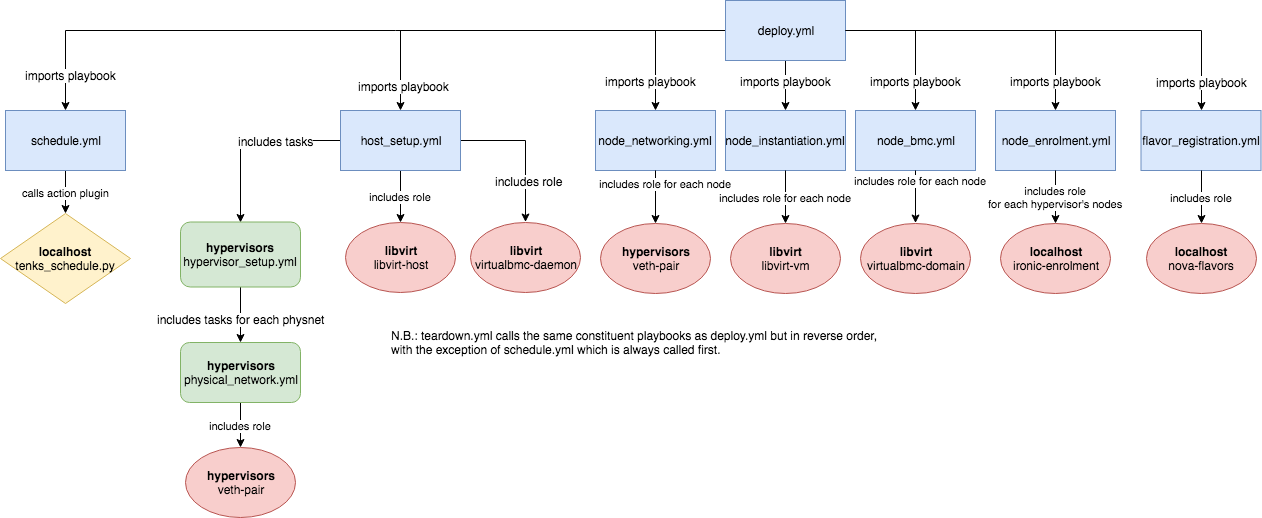
Architecture
The below diagram represents the interaction of the different Ansible
components within Tenks. The libvirt-vm and libvirt-host roles are imported
from StackHPC's Ansible Galaxy collection12; the rest are internal to
Tenks.
Networking
To allow testing of a wider range of scenarios, we decided it was important that Tenks support multihomed nodes. This would represent an improvement on the capabilities of DevStack, by allowing an arbitrary number of networks to be configured and connected to any node.
Tenks has a concept of 'physical network' which currently must map one-to-one to the hardware networks plugged into the hypervisors. It requires device mappings to be specified on a hypervisor for each physical network that is to be connected to nodes on that hypervisor. This device can be an interface, a Linux bridge or an Open vSwitch bridge. For each physical network that is given a mapping on a hypervisor, a new Tenks-managed Open vSwitch bridge is created. If the device mapped to this physnet is an interface, it is plugged directly into the new bridge. If the device is an existing Linux bridge, a veth pair is created to connect the existing bridge to the new bridge. If the device is an existing Open vSwitch bridge, an Open vSwitch patch port is created to link the two bridges.
A new veth pair is created for each physical network that each node on each hypervisor is connected to, and one end of the pair is plugged into the Tenks Open vSwitch bridge for that physical network; the other end will be plugged into the node itself. Creation of these veth pairs is necessary (at least for the Libvirt provider) to ensure that an interface is present in Open vSwitch even when the node itself is powered off.
 |
|---|
| An example of the networking structure of Tenks. In this example, one node was requested to be connected to physnet0 and physnet1, and two nodes were requested to be connected just to physnet1. |
Desirable Extensions
There are many features and extensions to the functionality of Tenks that I would make if I had more time at StackHPC. A few examples of these follow.
More Providers and Platform Management Systems
As mentioned earlier, it would be useful to extend Tenks to support providers other than Libvirt/QEMU/KVM - for example, VirtualBox, VMware or OpenStack. Redfish is also gaining momentum in the Ironic community as an alternative to IPMI-over-LAN, so adding support for this to Tenks would widen its appeal.
Increased Networking Complexity
As described in the Networking section above, making the assumption that each network to which nodes are connected will have a physical counterpart imposes some limitations. For example, if a hypervisor has fewer interfaces than physical networks exist in Tenks, either one or more physical networks will not be usable by nodes on that hypervisor, or multiple networks will have to share the same interface, breaking network isolation.
It would be useful for Tenks to support more complex software-defined networking. This could allow multiple 'physical networks' to safely share the same physical link on a hypervisor. VLAN tagging is used by certain OpenStack networking drivers (networking-generic-switch, for example) to provide tenant isolation for instance traffic. While this in itself is outside of the scope of Tenks, it would need to be taken into account if VLANs were also used for network separation in Tenks, due to potential gotchas when using nested VLANs.
More Intelligent Scheduling
The current system used to choose a hypervisor to host each node is rather naïve: it uses a round-robin approach to cycle through the hypervisors. If the next hypervisor in the cycle is not able to host the node, it will check the others as well. However, the incorporation of more advanced scheduling heuristics to inform more optimal placement of nodes would be desirable. All of Ansible's gathered facts about each hypervisor are available to the scheduling plugin, so it would be relatively straightforward to use facts about total/available memory or CPU load to shift the load balance towards more capable hypervisors.
Evaluation
Overall, I'm happy with the progress I've been able to make during my internship. The rest of the team has been very welcoming and I've got a lot out of the experience (special thanks to Mark for supervising and painstakingly reviewing all my pull requests!). Roughly the first half of my time here was spent reacquainting myself with OpenStack and the technologies around it, by way of performing test OpenStack deployments with various configurations on a virtual machine and preparing patches to be submitted upstream to fix issues as I encountered them. While this process meant that I didn't spend my entire internship working directly on Tenks, it was a very useful opportunity to 'dip my toes' back into the OpenStack ecosystem and it helped to shape the design decisions I made later on when developing Tenks.
Due to the time constraints of my placement, the initial work on Tenks was started outside of the OpenStack ecosystem. It has been an enjoyable summer project, but it would be more gratifying to see it continue in development and use not only within the company, but hopefully with the OpenStack community as an upstream project. Feel free to check out the project repository13 and read the documentation about contribution if you'd like to get involved. Finally, to my colleagues at StackHPC: so long and Tenks for all the fish!