For optimal reading, please switch to desktop mode.
As part of StackHPC's ongoing work on the Dawn supercomputer as part of the AIRRFED project, significant development has been invested into providing federated multi-tenant access to AI resources within a shared environment. One of the challenges of this project is the large and highly diverse set of modern use cases for HPC resources. This means a story is needed for anything from accessing a single JupyterLab instance to visualise some data to deploying an entire production-ready Kubernetes cluster within a Trusted Research Environment (TRE).
Our proposal for accommodating these demands was to partition resources into:
- Nodes reserved for TRE users to provision isolated Kubernetes clusters using upcoming OIDC features in StackHPC's Azimuth self-service portal.
- A Slurm cluster for running MPI-based training and inference workloads.
- A baremetal Kubernetes cluster for self-service deployment of common scientific computing applications, such as JupyterHub, Kubeflow and LLMs, through Azimuth.
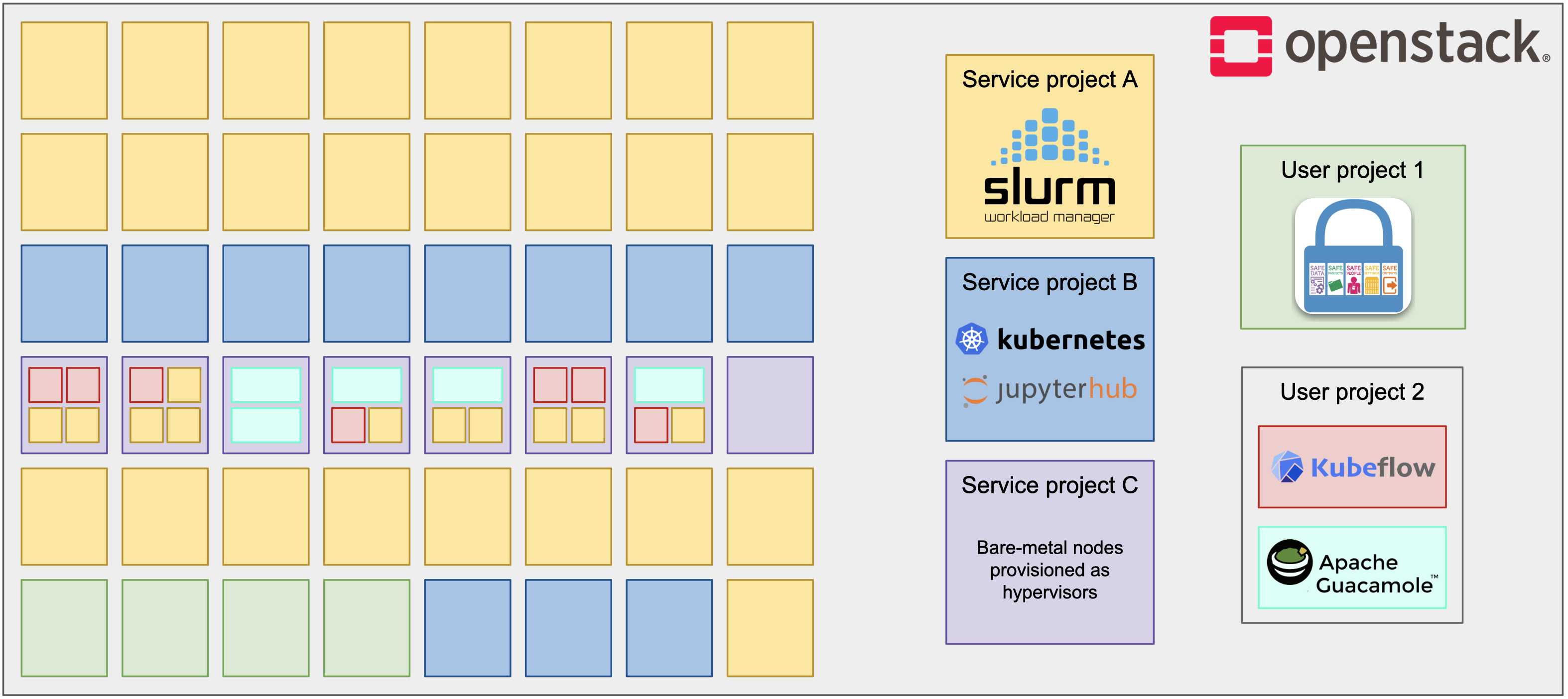
A modern HPC-AI infrastructure can be dynamically partitioned according to demand or allocation of resources in a controllable and flexible fashion.
This model provides interactive flexibility for users but raises questions of utilisation. Some idleness in nodes reserved for TREs may be a necessary evil to provide sufficient isolation for the 'T' part of the acronym to hold. But if the nodes reserved for self-service applications aren't continuously fully utilised, it means that resources are allocated but idle - capacity locked away from the rest of the infrastructure.
This is unfair to Slurm users, stuck for days waiting for batch jobs to run in a long queue. Idle capacity must be reclaimed and enrolled into service for batch scheduling.
Conversely, we need to preserve the interactive nature of user applications when they are needed, alongside their performance and security.
A solution is therefore needed to allow unused resources within a Kubernetes cluster to be automatically backfilled, but preempted by self-service applications when necessary. For this purpose, StackHPC has been evaluating SchedMD's Slinky, a set of open source projects for providing containerised, autoscaling Slurm clusters in Kubernetes. We have been developing a proof-of-concept to allow nodes to be taken out of the self-service pool and used in a common, cross-tenancy Slurm cluster, while using some Kubernetes scheduling smarts to ensure exclusive access can be given back to self-service users within tenancies as soon as it is required.
Through this we came to the conclusion that while some odd interactions between Slinky and Kubernetes' scheduling mean that it isn't currently suitable for this purpose, some exciting new features in Slinky could make it into a promising solution down the line.
Scaling Up With Slinky
Slinky is a set of projects used to deploy Slurm clusters over Kubernetes, allowing them to take advantage of K8s' powerful scheduling and scaling capabilities (and completely eating the lunch of the work StackHPC was doing to deploy Slurm over Kubernetes!). The project works by using an operator to deploy Helm-managed Slurm clusters. Once deployed, the number of pods/nodes to allocate to a cluster can be managed by setting the replica count for the cluster's NodeSet object in the cluster's Helm values, as you would for standard Kubernetes workloads:
compute:
nodesets:
- name: my-nodeset
replicas: 3
This conveniently allows nodesets to be managed by a K8s Horizontal Pod Autoscaler (HPA) and be configured to scale up to meet the demands of pending jobs. If a nodeset's nodeSelector field allows it, this can include the nodes used in the pool used for self-service apps. Slinky reccomends using Keda autoscaler, which allows the cluster to be scaled up based on triggers from Slinky's exported Prometheus metrics. The simplest way to do this is to define a trigger to scale up the cluster when pending jobs are detected in the queue, for example:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: my-nodeset-radar
spec:
scaleTargetRef:
apiVersion: slinky.slurm.net/v1alpha1
kind: NodeSet
name: slurm-compute-my-nodeset
idleReplicaCount: 0
minReplicaCount: 0
maxReplicaCount: 3 # total number of nodes you wish to be allocable
cooldownPeriod: 3000 # set to max job time of cluster
triggers:
- type: prometheus
metricType: Value
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.prometheus:9090
query: slurm_partition_pending_jobs{partition="my-nodeset"}
threshold: '1'
This configuration will begin scaling up from zero nodes, continuing to scale up to a maximum of three while at least one job remains pending in the queue. While Keda is useful for event-based scaling up of a cluster, it's somewhat limited in that it doesn't currently allow triggers to be defined to scale the cluster back down again, instead simply beginning to scale back down again when the trigger condition remains false for the cooldownPeriod. Ideally, we would only want to scale the cluster back down again only once allocated nodes become idle, but the current configuration will simply start scaling down when no jobs are left in the queue, even if jobs are still executing. To work around this, the cooldownPeriod can be set to the maximum job time of the Slurm partition, meaning that jobs won't be cancelled by nodes prematurely scaling down. The obvious downside of this approach is that idle nodes will remain in the cluster for extended periods. This, however, can be worked around with a preemption strategy as discussed below. We plan to iterate on this approach to try and develop a solution that scales the cluster based on a more accurate view of user demand.
Another, more problematic, limitation of Slinky was also found during our evaluation. Due to Kubernetes having no native way of delegating control of cgroup subtrees to pods, Slinky can't enable Slurm's cgroup plugins as most production clusters would. Therefore, cgroup resource constraints can only be strictly enforced at a pod level i.e for the total resource usage of all batch jobs on the node. This significantly limits slurmstepd's ability to constrain resources at a per-job level, which may be unacceptable unless your use case can tolerate arbitrary resource usage by any job.
The Applications Take Back What's Theirs
The batch users have had their fun and now the interactive self-service users want their nodes back to run apps on. Under the current configuration, Slinky compute pods can be scheduled on the same nodes as the application pods, degrading their performance and potentially allowing for all manner of nasty side channel attacks. In theory, there are some nifty Kubernetes scheduling tricks we could use to ensure Slinky pods get evicted. However, these have proven problematic due to the complex interactions between the scheduling of Slinky and various common HPC apps. The obvious solution is to use a podAntiAffinity to ensure that Slinky compute pods can't be scheduled onto the same node as pods deployed by self-service users. For example, we could mark all pods from self-service apps with a label and then give the Slinky compute pods a podAntiAffinity for that label:
compute:
nodesets:
- name: my-nodeset
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: stackhpc.com/application-pod
operator: In
values:
- true
However, all anti-affinities are ignored during execution. Since, in this scenario, the Slinky compute pod is already on the node, the anti-affinity just means that the application's pod won't get scheduled. Even if this conflict occured while both pods were initially being scheduled, the scheduler has no reason to prioritise scheduling the application pod, so which pod gets the node will be decided arbitrarily. We therefore need a way to ensure that Slinky pods are preempted by the application pods. We can achieve this using priorityClasses. If pods can't be scheduled but have a priorityClass with a higher priority value than pods already on the node, the scheduler is able to evict existing pods. To minimise the extra configuration this requires, we can just create a priority class for Slinky compute pods with a lower priority than the default of 0, so that any pending pod can preempt it:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: slinky-low-priority
value: -1
globalDefault: false
And after applying this to the Slinky compute pods:
compute:
nodesets:
- name: my-nodeset
priorityClass: "slinky-low-priority"
A Schedule Clash
Now, from our understanding of the Kubernetes docs, this should mean that if we deploy our self-serviced application pods with the appropriate label, they will be able to preempt the Slinky pods and run without fear of their services being degraded. But in reality, scheduling is not quite so simple. In our test case, we attempted to preempt Slinky pods with a JupyterHub user server. This case introduced the complication of both of the pods of interest being spawned by calls to the Kubernetes API from their respective services rather than standard Kubernetes workloads such as Deployments or DaemonSets. While the Jupyter pod was consistently able to evict the Slinky pod initially, the Slinky pod then immediately attempts to reschedule, resulting in VERY race-prone scheduling. We observed that the pods were at times able to outright ignore the anti-affinity and schedule on the same node! This is presumably a consequence of race conditions meaning that the two pods aren't aware of each other's scheduling constraints at the time of creation and not being able to gracefully reschedule due to not being managed by workloads.
A partial workaround was found to this issue, but it came with its own set of horrible race conditions. If the two pods have their resource requests set such that they are unable to be scheduled on the same node (e.g by both requesting all GPUs on a node), this appears to be respected during initial creation, almost acting as a mutex to prevent both pods from being scheduled onto the node before their anti-affinities are recognised. But while the pods can no longer schedule onto the same node, they are still racing to actually claim the resources. This causes a new issue where:
- The application pod preempts the Slinky pod
- The Slinky pod immediately reschedules
- If the Slinky pod wins the race for resources, it reschedules onto the node...
- But is immediately evicted again
- And the application pod gets stuck in Pending while steps 3 and 4 repeat indefinitely
So it's safe to say this isn't a production ready solution just yet. We're aware that backfilling is a hot topic in HPC at the moment and that similar issues may have been hit before, so if you happen to have any insight into this problem we would love to hear from you via our contact page below.
Bridging the Gap
But while these scheduling quirks mean that Slinky isn't currently appropriate for backfilling in many use cases, native features are on the way which will make it a much more appealing option in future releases. SchedMD have revealed Slurm Bridge, a Kubernetes scheduling plugin putting scheduling under Slurm's control. Set to release in June 2025, it explicitly advertises features to allow for backfilling and running converged Slurm and Kubernetes clusters with separation of workloads enforced through Multi-Category Security. This looks very promising for our use case and we will likely be re-evaluating Slinky once Bridge lands.
Conclusion
This approach gives an interesting potential solution to the problem of providing Kubernetes managed applications a secure, available pool of resources without sacrificing utilisation. While the discussed scheduling issues made Slinky not viable for this case at present, it appears to be shaping up to be a promising solution. The potential limitation of using Slinky for backfilling is that Slurm workloads can't tolerate losing nodes mid-job and must be rescheduled. This means that nodes added to Slinky's pool in this way aren't appropriate for running long-lived jobs, especially if resource usage by self-serviced apps is highly variable. This limitation may be prohibitive in a lot of cases, given the typical workloads run on Slurm clusters, but if partitioned appropriately it can nicely complement a stable cluster to ease queue times.
As a simplfied example, the Slinky cluster could have two partitions: one for your production workloads, one dynamic parition for backfilling opportunistic workloads, sharing the nodes used by interactive apps. This way you can satisfy users who need stable nodes for long-running jobs. Users with short-lived jobs that can quickly slot into the preemptible nodes before they're preempted. We are excited to see how real users will interact with this system and how we can develop this concept further.
Acknowledgements
This research was carried out on the Dawn AI supercomputer at Cambridge University with the support of Cambridge University Research Computing Services.
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via LinkedIn, Bluesky or directly via our contact page.