For optimal reading, please switch to desktop mode.
Deploying OpenStack infrastructures with containers brings many operational benefits, such as isolation of dependencies and repeatability of deployment, in particular when coupled with a CI/CD approach. The Kolla project provides tooling that helps deploy and operate containerised OpenStack deployments. Configuring a new OpenStack cloud with Kolla containers is well documented and can benefit from the sane defaults provided by the highly opinionated Kolla Ansible subproject. However, migrating existing OpenStack deployments to Kolla containers can require a more ad hoc approach, particularly to minimise impact on end users.
We recently helped an organization migrate an existing OpenStack Queens production deployment to a containerised solution using Kolla and Kayobe, a subproject designed to simplify the provisioning and configuration of bare-metal nodes. This blog post describes the migration strategy we adopted in order to reduce impact on end users and shares what we learned in the process.
Existing OpenStack deployment
The existing cloud was running the OpenStack Queens release deployed using CentOS RPM packages. This cloud was managed by a control plane of 16 nodes, with each service deployed over two (for OpenStack services) or three (for Galera and RabbitMQ) servers for high availability. Around 40 hypervisor nodes from different generations of hardware were available, resulting in a heterogeneous mix of CPU models, amount of RAM, and even network interface names (with some nodes using onboard Ethernet interfaces and others using PCI cards).
A separate Ceph cluster was used as a backend for all OpenStack services requiring large amounts of storage: Glance, Cinder, Gnocchi, and also disks of Nova instances (i.e. none of the user data was stored on hypervisors).
A new infrastructure
With a purchase of new control plane hardware also being planned, we advised the following configuration, based on our experience and recommendations from Kolla Ansible:
- three controller nodes hosting control services like APIs and databases, using an odd number for quorum
- two network nodes hosting Neutron agents along with HAProxy / Keepalived
- three monitoring nodes providing centralized logging, metrics collection and alerting, a feature which was critically lacking from the existing deployment
Our goal was to migrate the entire OpenStack deployment to use Kolla containers and be managed by Kolla Ansible and Kayobe, with control services running on the new control plane hardware and hypervisors reprovisioned and reconfigured, with little impact on users and their workflows.
Migration strategy
Using a small-scale candidate environment, we developed our migration strategy. The administrators of the infrastructure would install CentOS 7 on the new control plane, using their existing provisioning system, Foreman. We would configure the host OS of the new nodes with Kayobe to make them ready to deploy Kolla containers: configure multiple VLAN interfaces and networks, create LVM volumes, install Docker, etc.
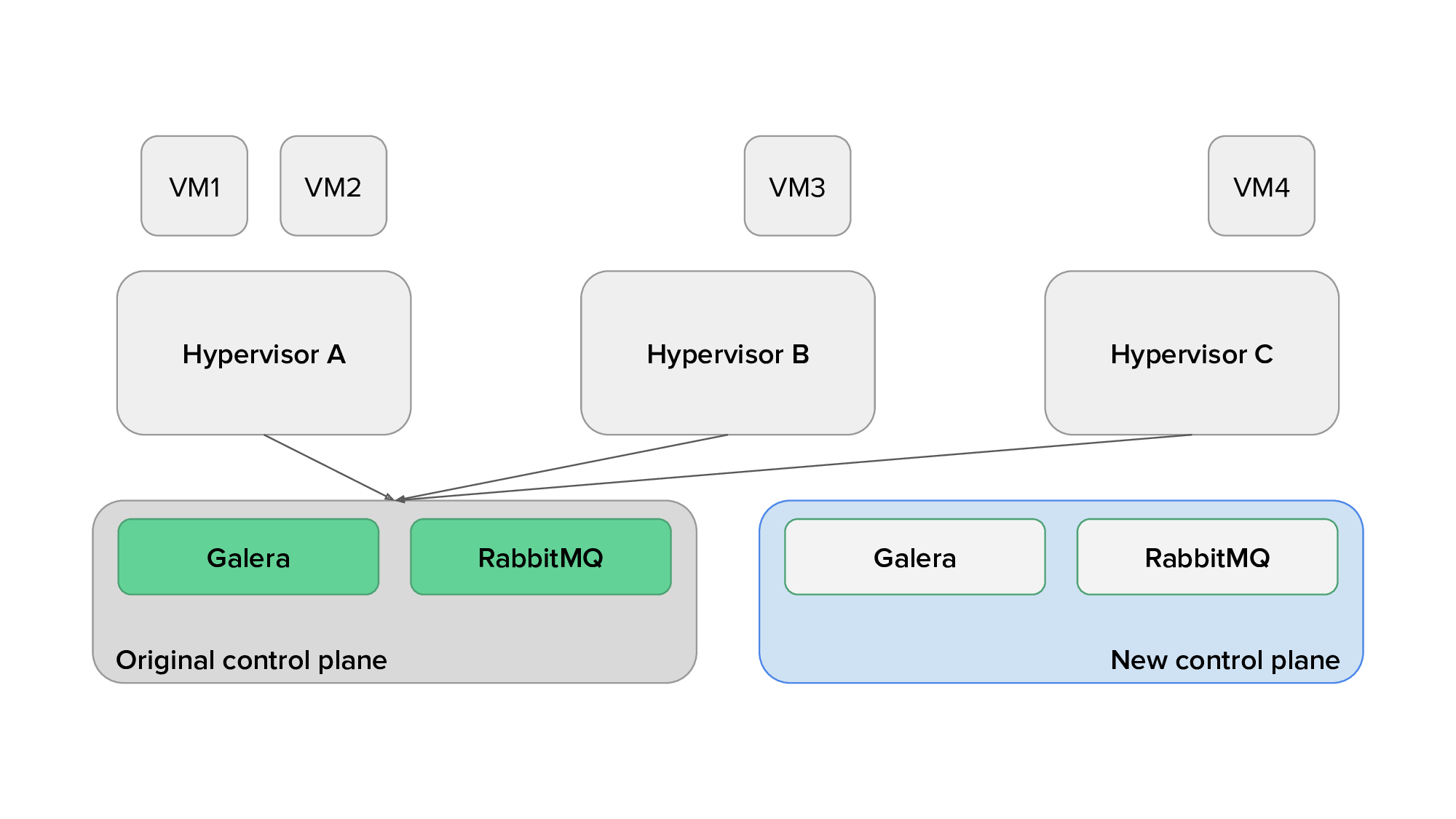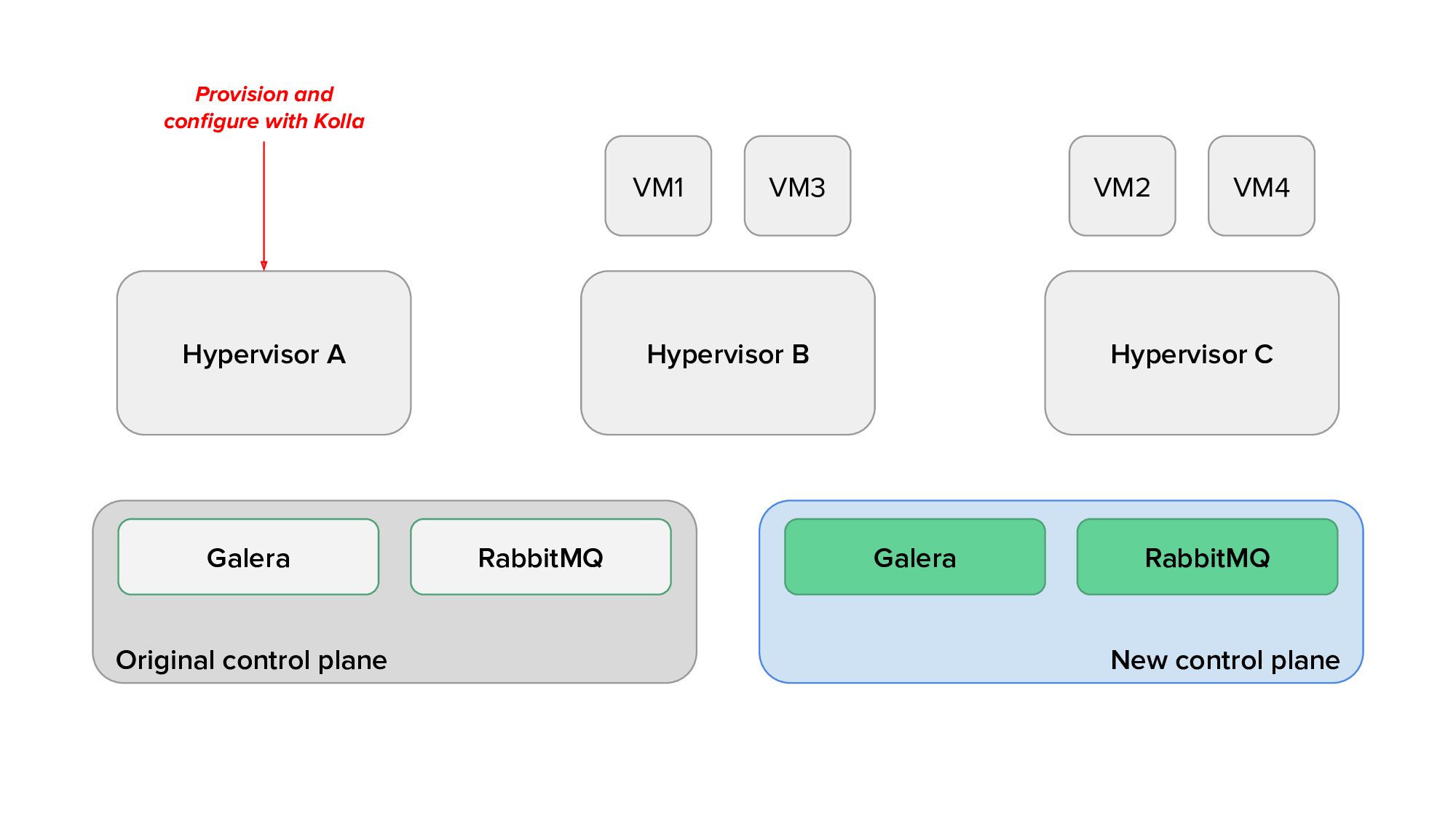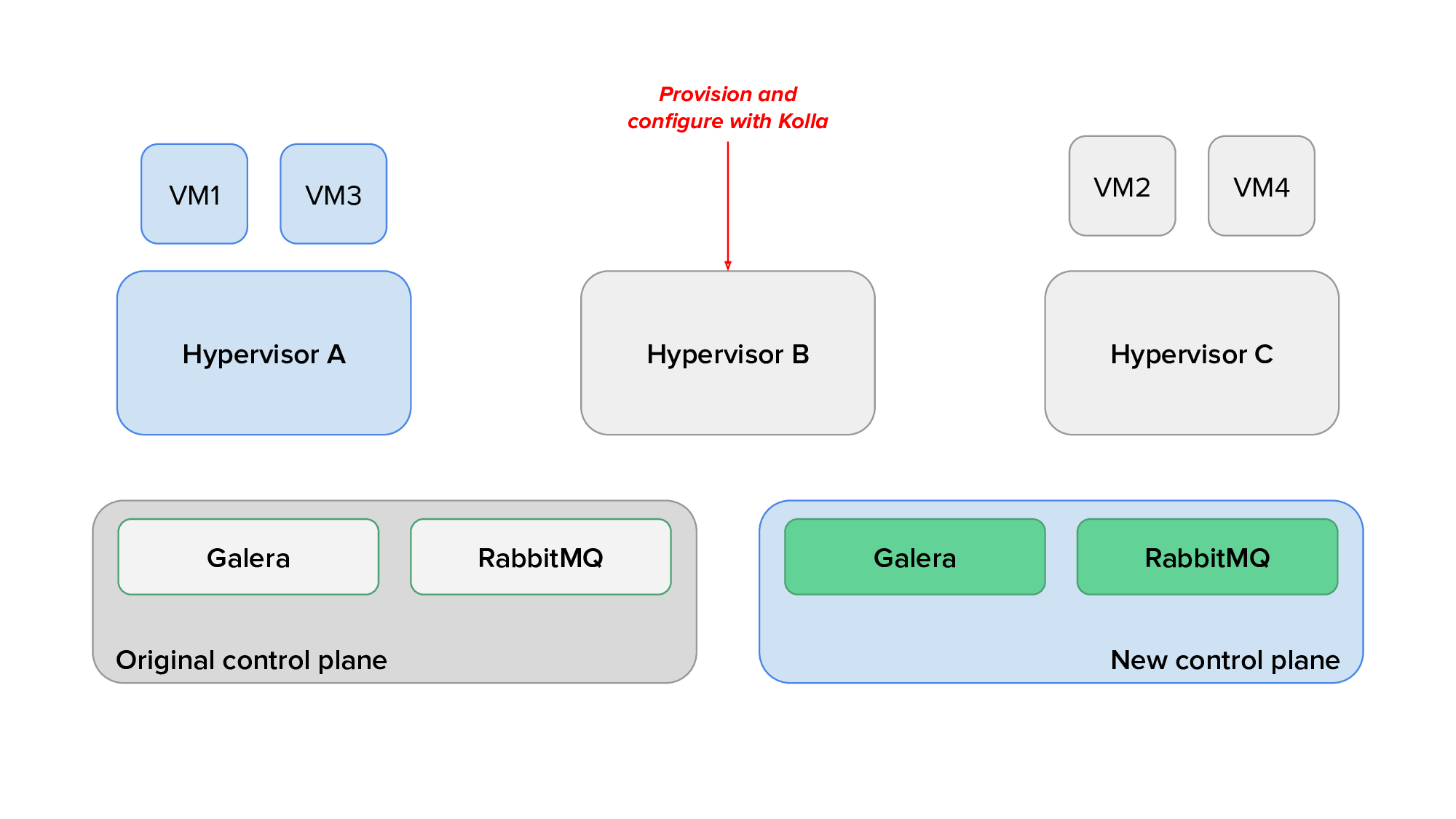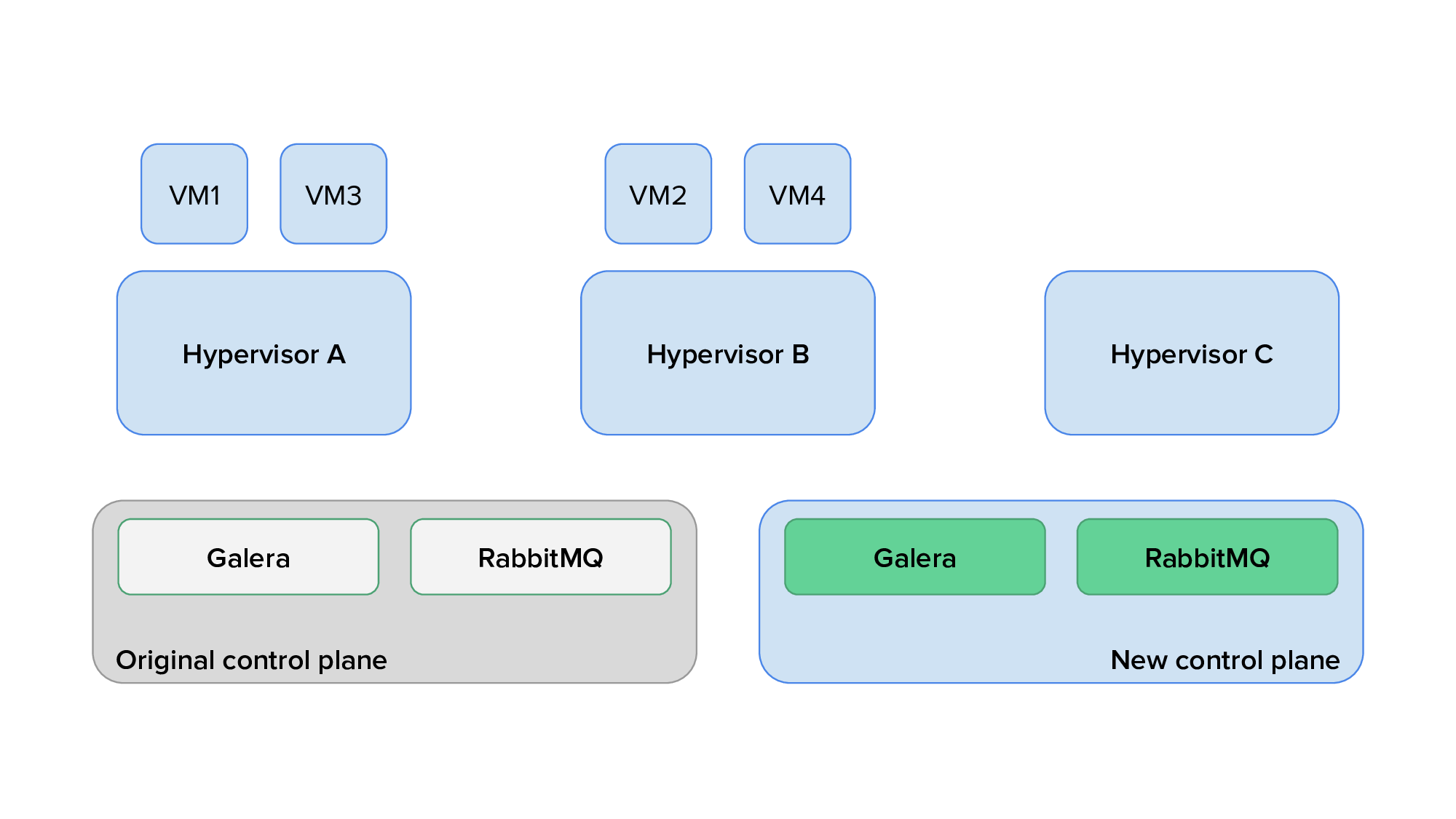
We would then deploy OpenStack services on this control plane. To reduce the risk of the migration, our strategy was to progressively reconfigure the load balancers to point to the new controllers for each OpenStack service while validating that they were not causing errors. If any issue arose, we would be able to quickly revert to the API services running on the original control plane. Fresh Galera, Memcached, and RabbitMQ clusters would also be set up on the new controllers, although the existing ones would remain in use by the OpenStack services for now. We would then gradually shut down the original services after making sure that all resources are managed by the new OpenStack services.
Then, during a scheduled downtime, we would copy the content of the SQL database, reconfigure all services (on the control plane and also on hypervisors) to use the new Galera, Memcached, and RabbitMQ clusters, and move the virtual IP of the load balancer over to the new network nodes, where HAProxy and Keepalived would be deployed.
The animation below depicts the process of migrating from the original to the new control plane, with only a subset of the services displayed for clarity.
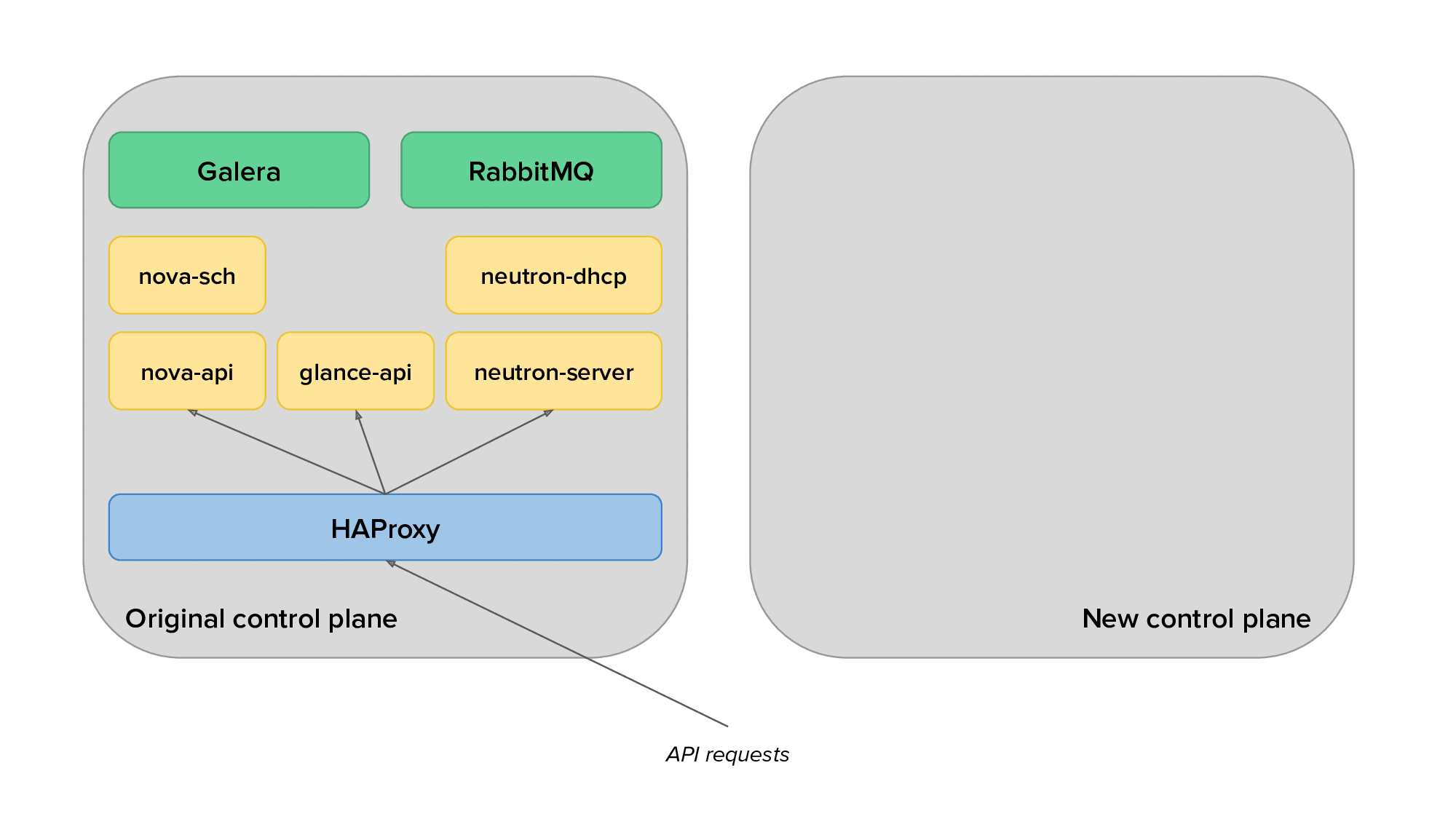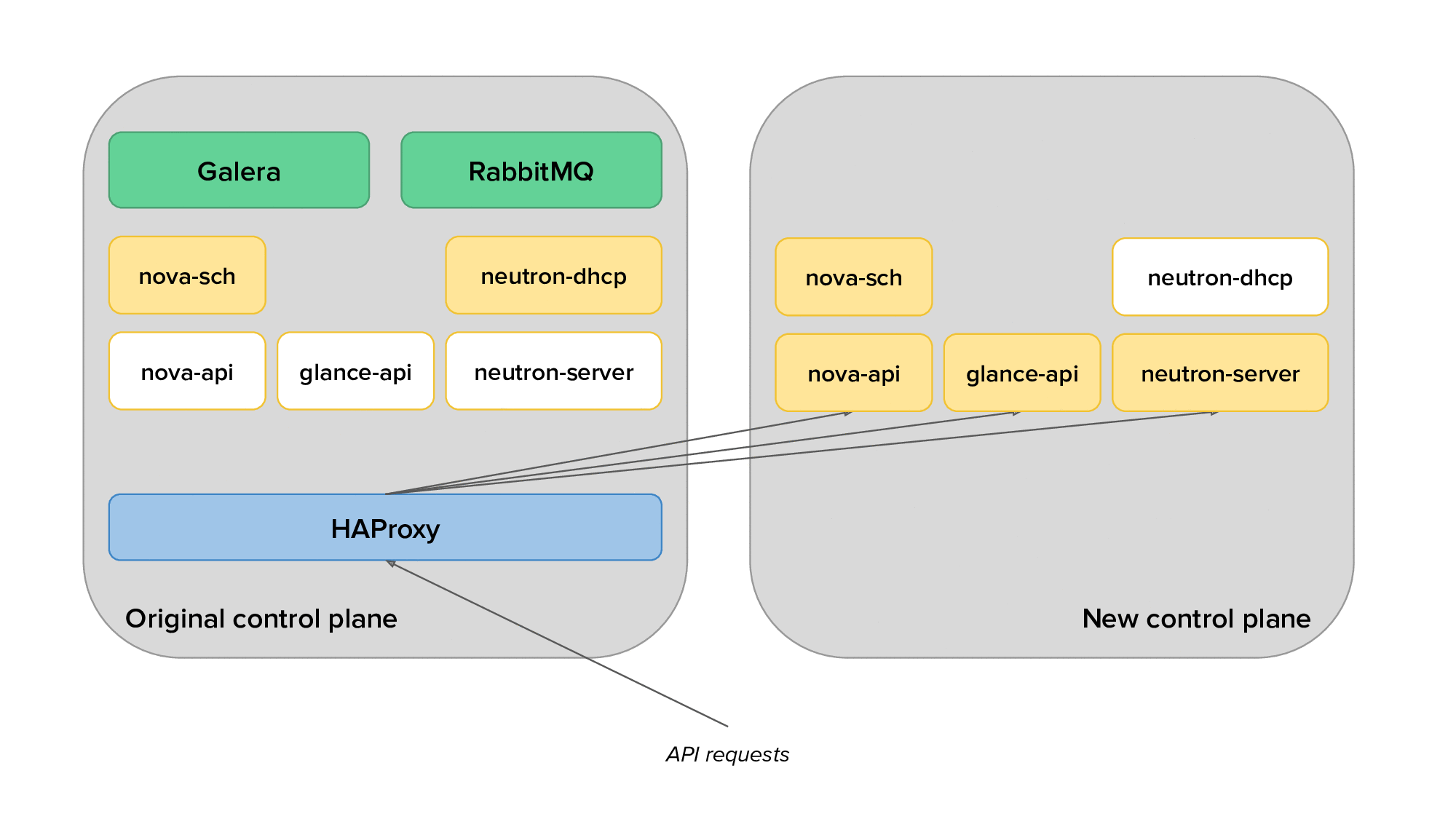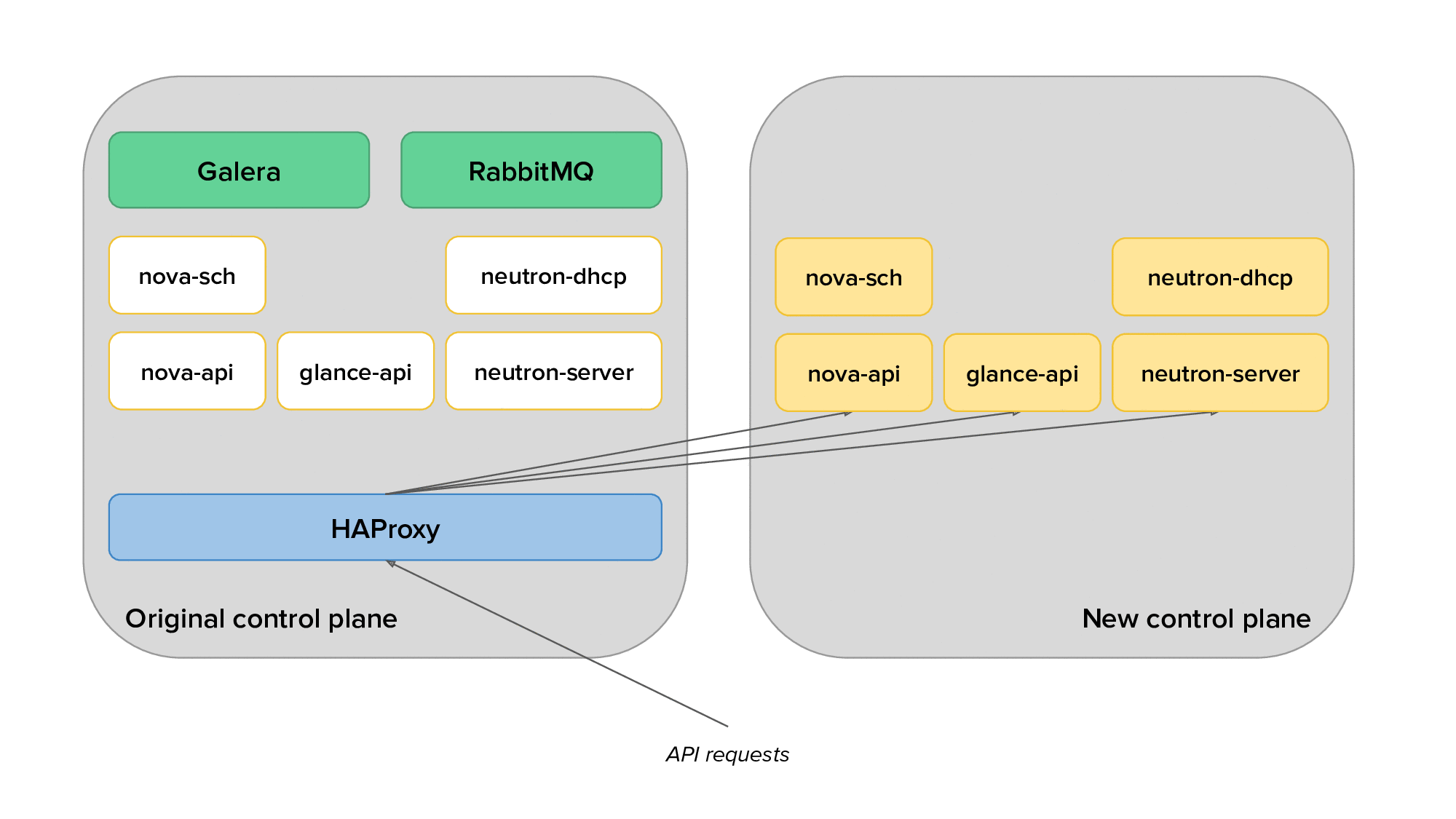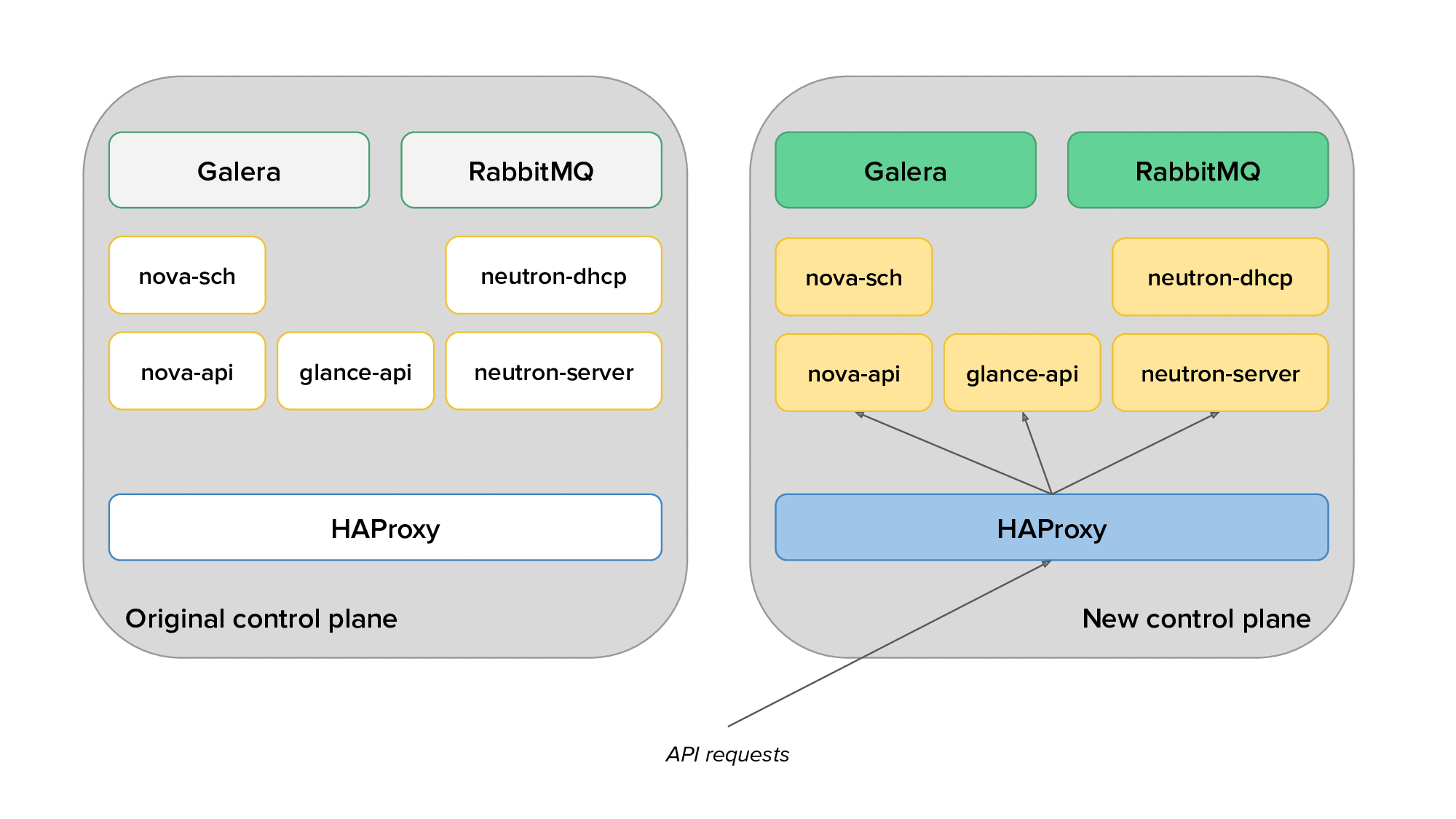
Finally, we would use live migration to free up several hypervisors, redeploy OpenStack services on them after reprovisioning, and live migrate virtual machines back on them. The animation below shows the transition of hypervisors to Kolla:
Tips & Tricks
Having described the overall migration strategy, we will now cover tasks that required special care and provide tips for operators who would like to follow the same approach.
Translating the configuration
In order to make the migration seamless, we wanted to keep the configuration of services deployed on the new control plane as close as possible to the original configuration. In some cases, this meant moving away from Kolla Ansible's sane defaults and making use of its extensive customisation capabilities. In this section, we describe how to integrate an existing configuration into Kolla Ansible.
The original configuration management tool kept entire OpenStack configuration files under source control, with unique values templated using Jinja. The existing deployment had been upgraded several times, and configuration files had not been updated with deprecation and removal of some configuration options. In comparison, Kolla Ansible uses a layered approach where configuration generated by Kolla Ansible itself is merged with additions or overrides specified by the operator either globally, per role (nova), per service (nova-api), or per host (hypervisor042). This has the advantage of reducing the amount of configuration to check at each upgrade, since Kolla Ansible will track deprecation and removals of the options it uses.
The oslo-config-validator tool from the oslo.config project helps with the task of auditing an existing configuration for outdated options. While introduced in Stein, it may be possible to run it against older releases if the API has not changed substantially. For example, to audit nova.conf using code from the stable/queens branch:
$ git clone -b stable/queens https://opendev.org/openstack/nova.git
$ cd nova
$ tox -e venv -- pip install --upgrade oslo.config # Update to the latest oslo.config release
$ tox -e venv -- oslo-config-validator --config-file etc/nova/nova-config-generator.conf --input-file /etc/nova/nova.conf
This would output messages identifying removed and deprecated options:
ERROR:root:DEFAULT/verbose not found
WARNING:root:Deprecated opt DEFAULT/notify_on_state_change found
WARNING:root:Deprecated opt DEFAULT/notification_driver found
WARNING:root:Deprecated opt DEFAULT/auth_strategy found
WARNING:root:Deprecated opt DEFAULT/scheduler_default_filters found
Once updated to match the deployed release, all the remaining options could be moved to a role configuration file used by for Kolla Ansible. However, we preferred to audit each one against Kolla Ansible templates, such as nova.conf.j2, to avoid keeping redundant options and detect any potential conflicts. Future upgrades will be made easier by reducing the amount of custom configuration compared to Kolla Ansible's defaults.
Templating also needs to be adapted from the original configuration management system. Kolla Ansible relies on Jinja which can use variables set in Ansible. However, when called from Kayobe, extra group variables cannot be set in Kolla Ansible's inventory, so instead of cpu_allocation_ratio = {{ cpu_allocation_ratio }} you would have to use a different approach:
{% if inventory_hostname in groups['compute_big_overcommit'] %}
cpu_allocation_ratio = 16.0
{% elif inventory_hostname in groups['compute_small_overcommit'] %}
cpu_allocation_ratio = 4.0
{% else %}
cpu_allocation_ratio = 1.0
{% endif %}
Configuring Kolla Ansible to use existing services
We described earlier that our migration strategy was to progressively deploy OpenStack services on the new control plane while using the existing Galera, Memcached, and RabbitMQ clusters. This section explains how this can be configured with Kayobe and Kolla Ansible.
In Kolla Ansible, many deployment settings are configured in ansible/group_vars/all.yml, including the RabbitMQ transport URL (rpc_transport_url) and the database connection (database_address).
An operator can override these values from Kayobe using etc/kayobe/kolla/globals.yml:
rpc_transport_url: rabbit://username:password@ctrl01:5672,username:password@ctrl02:5672,username:password@ctrl03:5672
Another approach is to populate the groups that Kolla Ansible uses to generate these variables. In Kayobe, we can create an extra group for each existing service (e.g. ctrl_rabbitmq), populate it with existing hosts, and customise the Kolla Ansible inventory to map services to them.
In etc/kayobe/kolla.yml:
kolla_overcloud_inventory_top_level_group_map:
control:
groups:
- controllers
network:
groups:
- network
compute:
groups:
- compute
monitoring:
groups:
- monitoring
storage:
groups:
"{{ kolla_overcloud_inventory_storage_groups }}"
ctrl_rabbitmq:
groups:
- ctrl_rabbitmq
kolla_overcloud_inventory_custom_components: "{{ lookup('template', kayobe_config_path ~ '/kolla/inventory/overcloud-components.j2') }}"
In etc/kayobe/inventory/hosts:
[ctrl_rabbitmq]
ctrl01 ansible_host=192.168.0.1
ctrl02 ansible_host=192.168.0.2
ctrl03 ansible_host=192.168.0.3
We copy overcloud-components.j2 from the Kayobe source tree to etc/kayobe/kolla/inventory/overcloud-components.j2 in our kayobe-config repository and customise it:
[rabbitmq:children]
ctrl_rabbitmq
[outward-rabbitmq:children]
ctrl_rabbitmq
While better integrated with Kolla Ansible, this approach should be used with care so that the original control plane is not reconfigured in the process. Operators can use the --limit and --kolla-limit options of Kayobe to restrict Ansible playbooks to specific groups or hosts.
Customising Kolla images
Even though Kolla Ansible can be configured extensively, it is sometimes required to customise Kolla images. For example, we had to rebuild the heat-api container image so it would use a different Keystone domain name: Kolla uses heat_user_domain while the existing deployment used heat.
Once a modification has been pushed to the Kolla repository configured to be pulled by Kayobe, one can simply rebuild images with the kayobe overcloud container image build command.
Deploying services on the new control plane
Before deploying services on the new control plane, it can be useful to double-check that our configuration is correct. Kayobe can generate the configuration used by Kolla Ansible with the following command:
$ kayobe overcloud service configuration generate --node-config-dir /tmp/kolla
To deploy only specific services, the operator can restrict Kolla Ansible to specific roles using tags:
$ kayobe overcloud service deploy --kolla-tags glance
Migrating resources to new services
Most OpenStack services will start managing existing resources immediately after deployment. However, a few require manual intervention from the operator to perform the transition, particularly when services are not configured for high availability.
Cinder
Even when volume data is kept on a distributed backend like a Ceph cluster, each volume can be associated with a specific cinder-volume service. The service can be identified from the os-vol-host-attr:host field in the output of openstack volume show.
$ openstack volume show <volume_uuid> -c os-vol-host-attr:host -f value
ctrl01@rbd
There is a cinder-manage command that can be used to migrate volumes from one cinder-volume service to another:
$ cinder-manage volume update_host --currenthost ctrl01@rbd --newhost newctrl01@rbd
However there is no command to migrate specific volumes only, so if you are migrating to a bigger number of cinder-volume services, some will have have no volume to manage until the Cinder scheduler allocate new volumes on them.
Do not confuse this command with cinder migrate which is designed to transfer volume data between different backends. Be advised that when the destination is a cinder-volume service using the same Ceph backend, it will happily delete your volume data!
Neutron
Unless Layer 3 High Availability is configured in Neutron, routers will be assigned to a specific neutron-l3-agent service. The existing service can be replaced with the commands:
$ openstack network agent remove router --l3 <old-agent-uuid> <router-uuid>
$ openstack network agent add router --l3 <new-agent-uuid> <router-uuid>
Similarly, you can use the openstack network agent remove network --dhcp and openstack network agent add network --dhcp commands for DHCP agents.
Live migrating instances
In addition to the new control plane, several additional compute hosts were added to the system, in order to provide free resources that could host the first batch of live migrated instances. Once configured as Nova hypervisors, we discovered that we could not migrate instances to them because CPU flags didn't match, even though source hypervisors were using the same hardware.
This was caused by a mismatch in BIOS versions: the existing hypervisors in production had been updated to the latest BIOS to protect against the Spectre and Meltdown vulnerabilities, but these new hypervisors had not, resulting in different CPU flags.
This is a good reminder that in a heterogeneous infrastructure, operators should check the cpu_mode used by Nova. Kashyap Chamarthy's talk on effective virtual CPU configuration in Nova gives a good overview of available options.
What about downtime?
While we wanted to minimize the impact on end users and their workflow, there were no critical services running on this cloud that would have needed a zero downtime approach. If it had been a requirement, we would have explored dynamically added new control plane nodes to the existing clusters before removing the old ones. Instead, it was a welcome opportunity to reinitialize the configuration of several critical components to a clean slate.
The road ahead
This OpenStack deployment is now ready to benefit from all the improvements developed by the Kolla community, which released Kolla 8.0.0 and Kolla Ansible 8.0.0 for the Stein cycle earlier this summer and Kayobe 6.0.0 at the end of August. The community is now actively working on releases for OpenStack Train.
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky or directly via our contact page.