For optimal reading, please switch to desktop mode.
With Cambridge University, StackHPC has been working on our goal of an HPC-enabled OpenStack cloud. I have previously presented on the architecture and approach taken in deploying the system at Cambridge, for example at the OpenStack days UK event in Bristol
Our project there uses Mellanox ConnectX4-LX 50G Ethernet NICs for high-speed networking. Over the summer we worked on our TripleO configuration to unlock the SR-IOV capabilities of this NIC, delivering HPC-style RDMA protocols direct to our compute instances. We also have Cinder volumes backed by the iSER RDMA protocol plugged into our hypervisors. Those components are working well and delivering on the promise of an HPC-enabled OpenStack cloud.
However, SR-IOV does not fit every problem. On ConnectX4-LX, virtual functions bypass all but the most basic of OpenStack's SDN capabilities: we can attach a VF to a tenant VLAN, and that's it. All security groups and other richer network functions are circumvented. Furthermore, an instance using SR-IOV cannot be migrated (at least not yet). We use SR-IOV when we want Lustre and MPI, but we need a generic solution for all other types of network. However, performance of virtualised networking has been particularly elusive for our project.... but read on!
In addition to SR-IOV networking, TripleO creates for us a more standard OpenStack network configuration: VXLAN-encapsulated tenant networks and a hierarchy of Open vSwitch bridges to plumb together the data plane. In this case we have two OVS bridges: br-int and br-tun.
Performance Analysis
A very simple test case reveals the performance we achieve over VXLAN. We spin up a couple of VMs on different hypervisors and use iperf to benchmark the bandwidth of single TCP stream between them.
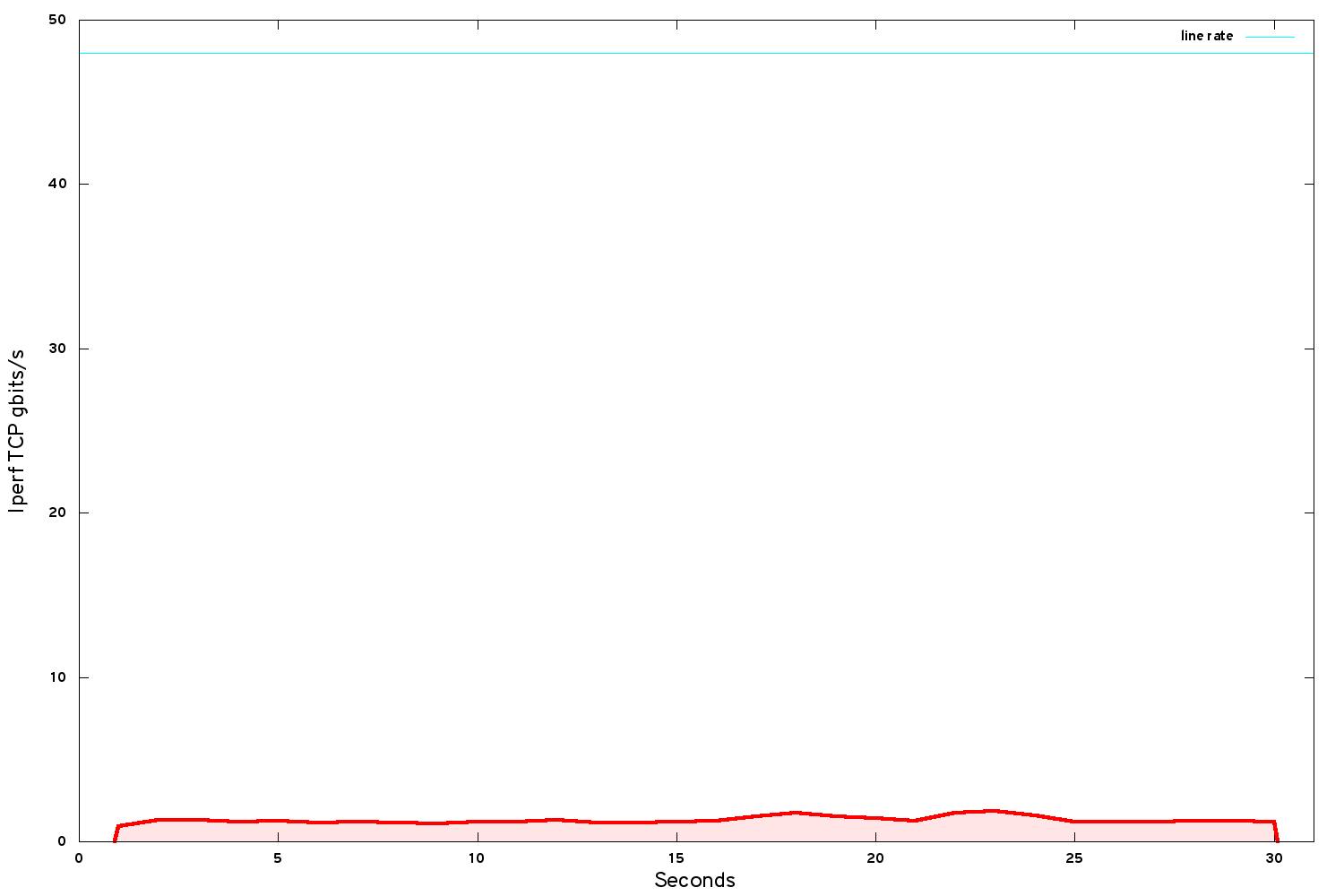
Despite using a 50G network, we hit about 1.2 gbits/s TCP bandwidth in our instances. Ouch! But wait - the Mellanox community website describes a use case, similar to the Cambridge use case but with an older version of NIC, delivering 20.51 gbits/s between VMs for VXLAN-encapsulated networking.
Something had to be done...
We started low-level. We took the Mellanox tuning guide for BIOS and kernel settings. Prinicipally this involved turning off all the hardware power-saving features, plus a chipset mode that adversely affects the performance of the Mellanox NIC.
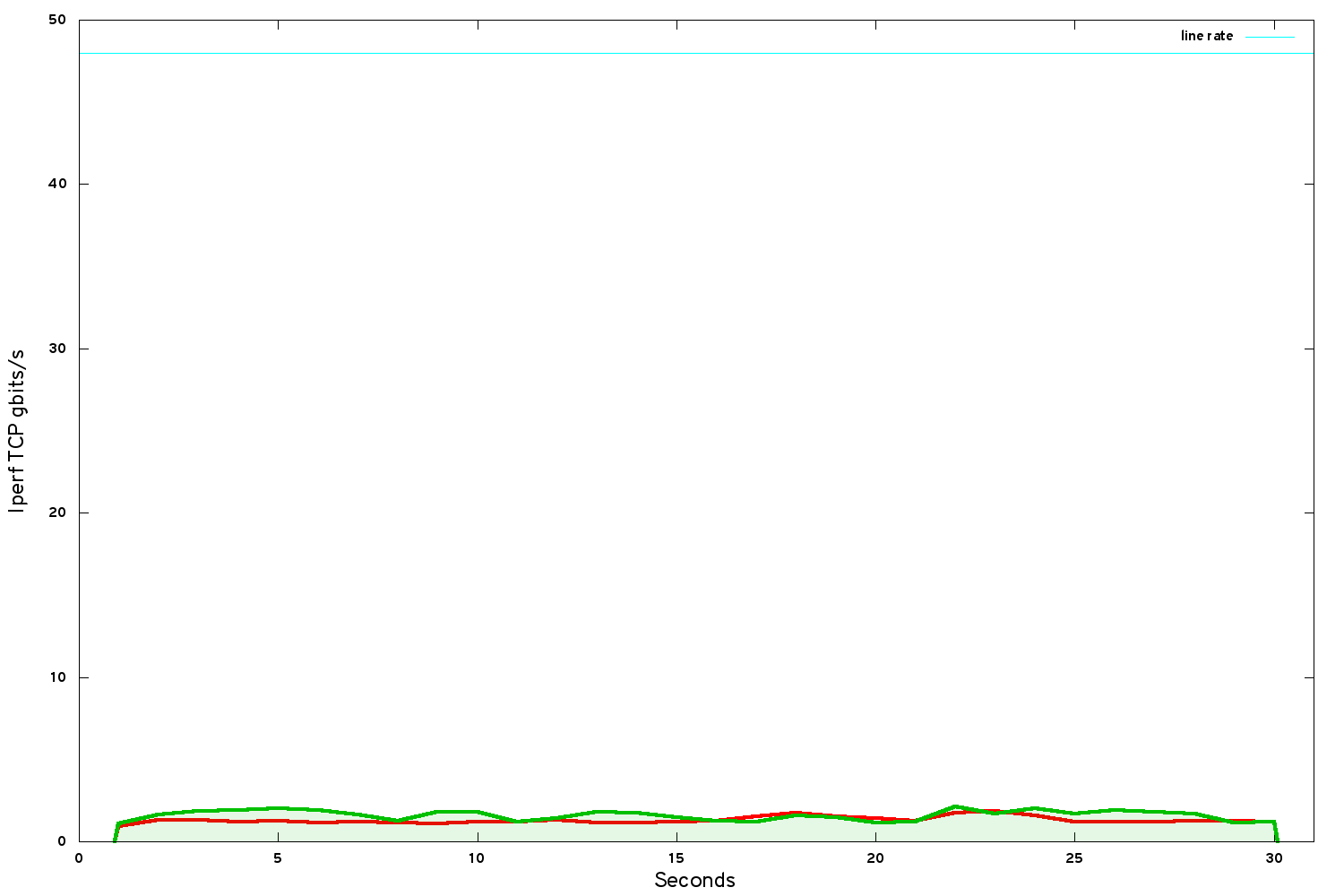
On our hardware this delivered roughly another 0.5 gbits/s: relatively a decent improvement, but still far from where we needed to be in absolute terms.
A perf profile and flame graph of the host OS provides insight into the overhead incurred by VXLAN, Open vSwitch and the software-defined networking performed in the hypervisor:
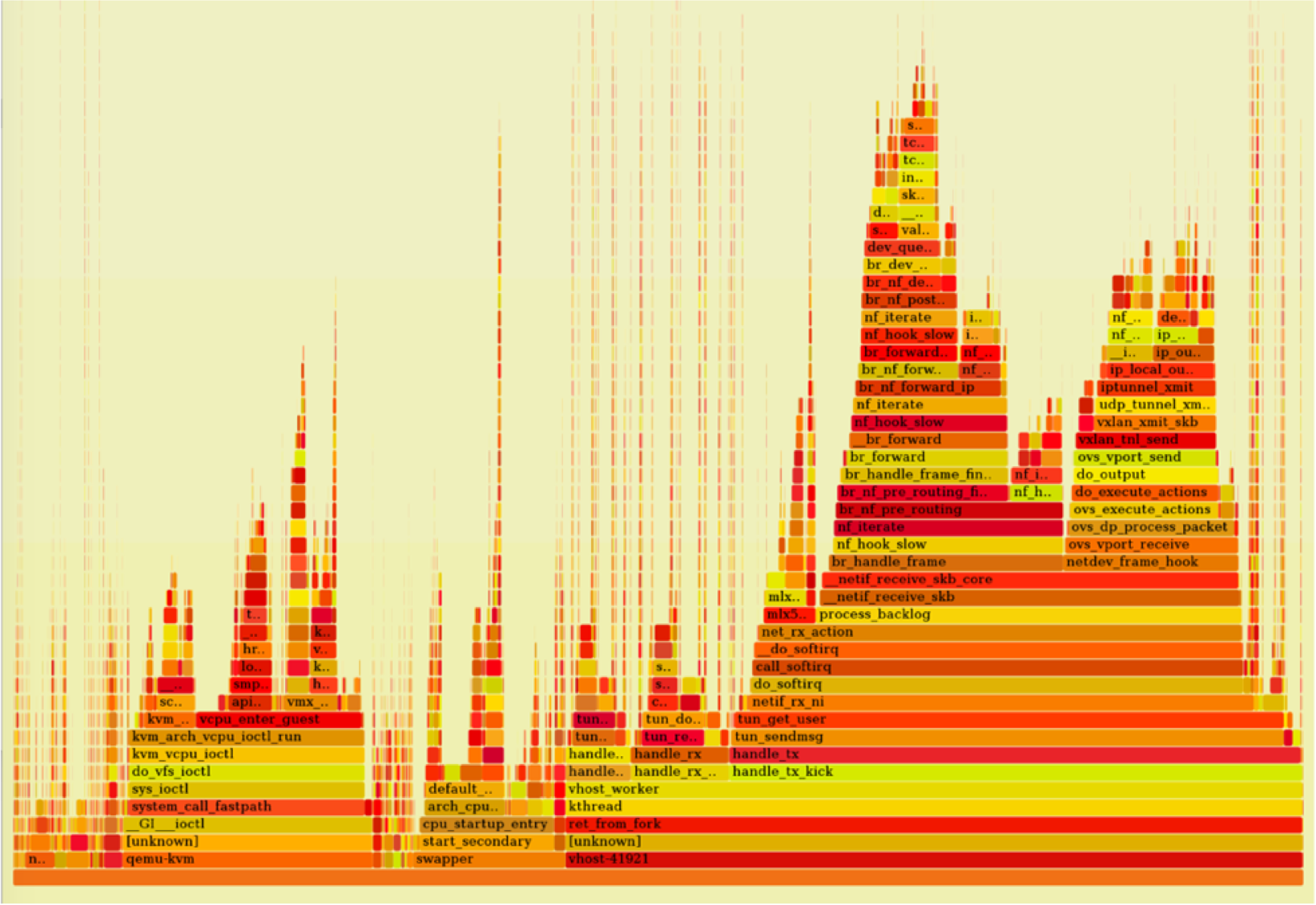
In this profile, the smaller "flame" on the left is time spent in the guest VM (where iperf is running), while the larger "flame" on the right is time spent in service of OVS and hypervisor networking. The relative width of each - not the height - is the significant metric. The bottleneck is the software-defined networking in the host OS.
The team at Mellanox came up with a breakthrough: our systems, based on RHEL 7 and CentOS 7, have a kernel that lacks some features developed upstream for efficient hardware offloading of VXLAN-encapsulated frames. We migrated a test system to kernel 4.7.10 and Mellanox OFED 3.5 - and saw a step change:
This is a good improvement to about 11 gbits/s - except that changing the kernel breaks supportability for Cambridge's production environment. For our own interest, we continued the investigation in order to know the untapped potential of our system.
The question of hyperthreading divides the HPC and cloud worlds: in HPC, it is almost never enabled but in cloud it is almost always enabled. By disabling it, we saw a surprisingly big uplift in performance to about 18.3 gbits/s (but we halved the number of cores in the system at the same time).
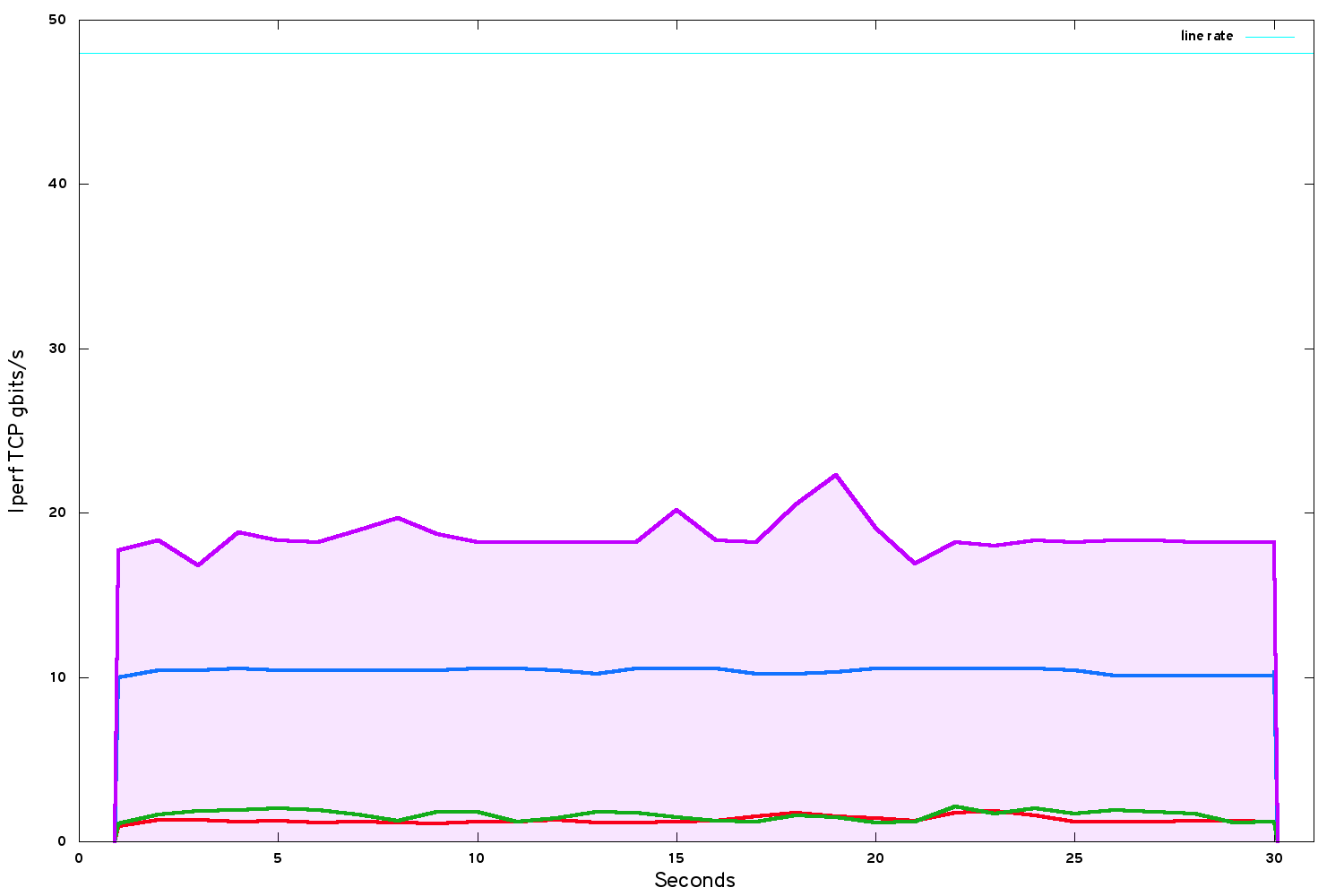
The performance with hyperthreading disabled has jumped higher, but has also become quite erratic. I guessed that this was because the system does not yet pin virtual CPU cores onto physical CPU cores. In Nova this is easily done (Kilo versions or later). A clearly-written blog post by Steve Gordon of Red Hat describes the next set of optimisations, although CPU pinning is relatively straightforward to implement.
On each Nova compute hypervisor, update /etc/nova/nova.conf to set vcpu_pin_set to a run-length list of CPU cores to which QEMU/KVM should pin the guest VM processes.
On our system, we tested with pinning guest VMs to cores 4-23, ie leaving 4 CPU cores 0-3 exclusively available to the host OS:
vcpu_pin_set=4-23
We also make sure that the host OS has RAM reserved for it. In our case, we reserved 2GB for the host OS:
reserved_host_memory_mb=2048
Once these changes are applied, restart the Nova compute service on the updated hypervisor:
systemctl restart openstack-nova-compute
To select which instances get their CPUs pinned, tag the images with metadata such as hw_cpu_policy
glance image-update <image ID> --property hw_cpu_policy=dedicated
(Steve Gordon's blog describes the alternative approach in which Nova flavors are tagged with hw:cpu_policy=dedicated, and then scheduled to specific availability zones tagged for pinned instances. In our use case we schedule them across the whole system instead).
After we had pinned all the VCPUs onto physical cores, performance was steady again but (surprisingly to me) no higher:
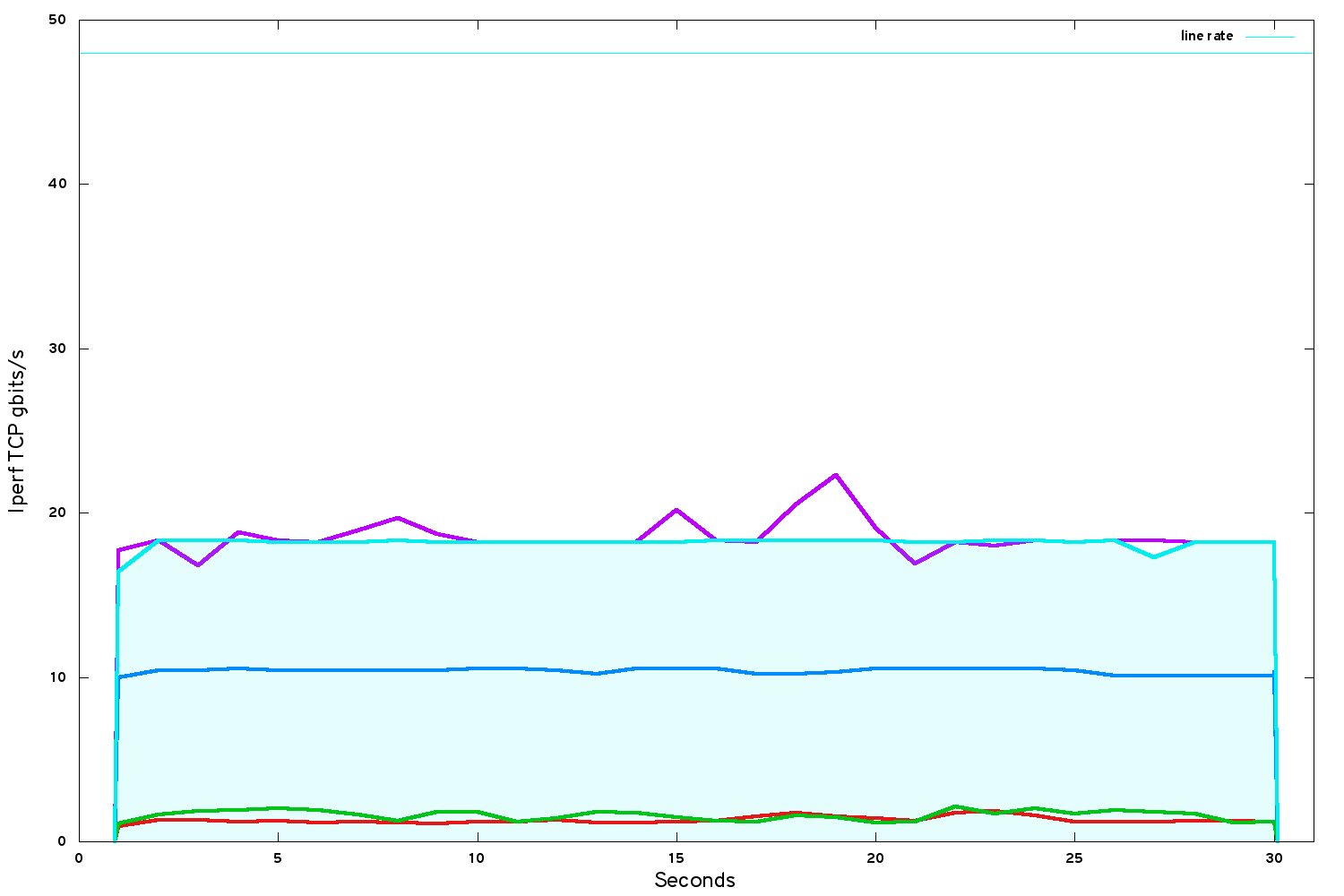
There are more optimisations available in the hypervisor environment. Finally we tried a few more of these:
Isolate the host OS from the cores to which guest VMs are pinned. This is done by updating the kernel boot parameters (and rebooting the hypervisor). Taking the CPU cores provided to Nova in vcpu_pin_set, pass them to the kernel using the command-line boot parameter isolcpus
isolcpus=4-23
After rebooting, htop (or similar) should demonstrate scheduling is confined to the CPUs specified.
Pass-through of NUMA: this requires some legwork on CentOS systems, because the QEMU version that ships with CentOS 7.2 (at the time of writing, 1.5.3) is too old for Nova, which requires a minimum of 2.1 for NUMA (and handling of huge pages).
The packages from the CentOS 7 virt KVM repo bring a CentOS system up to spec with a sufficiently recent version of QEMU-KVM for Nova's needs.
After enabling CPU isolation and NUMA passthrough, we get another boost:
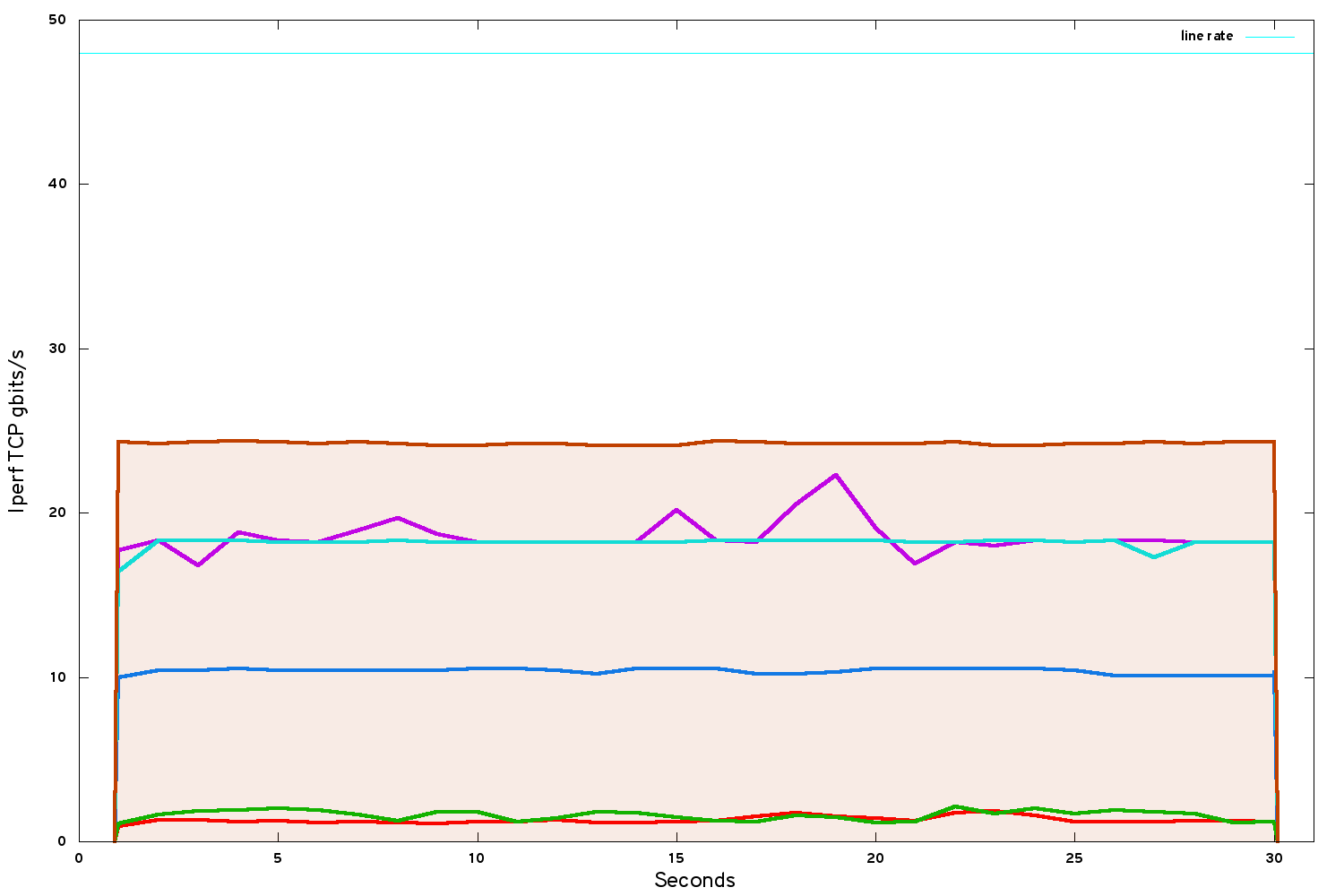
The instance TCP bandwidth has risen to about 24.3 gbits/s. From where we started this is a big improvement. But we are only at 50% line rate - we are still losing half our ultimate performance.
Alternatives to VXLAN and OVS
There are other software-defined networking options that don't use OVS (or indeed VXLAN), and I am researching those capabilities with the hope of evaluating them in a future project.
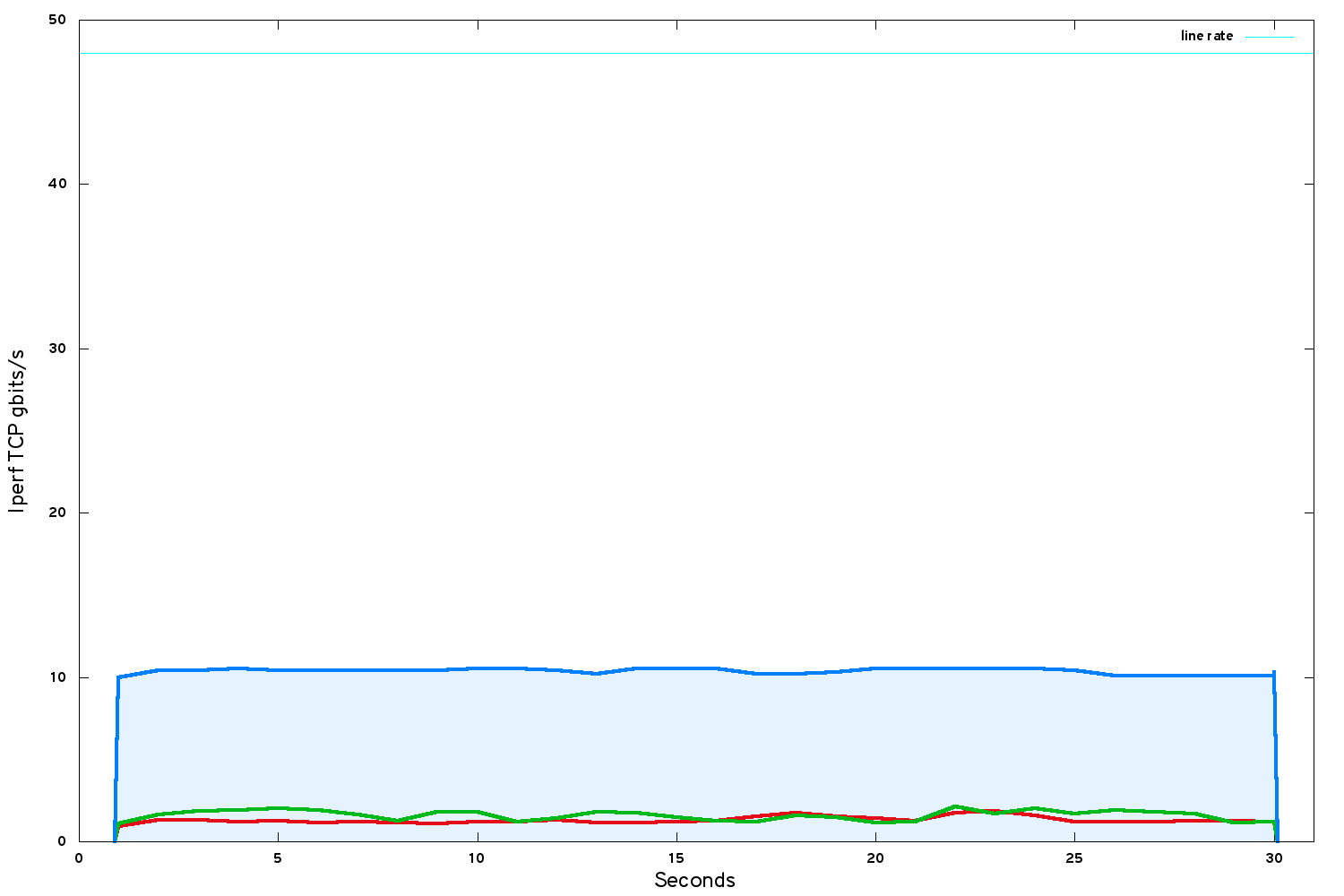
Using modern high-performance Ethernet NICs, SR-IOV delivers a far greater level of performance. However, that performance comes at a cost of convenience and flexibility.
- As mentioned previously, SR-IOV bypasses security groups and associated rich functionality of software-defined networking. It should not be used on any network that is intended to be externally visible.
- Using SR-IOV currently prevents the live migration of instances.
- Our Mellanox ConnectX-4 LX NICs only support SR-IOV in conjunction with VLAN tenant network segmentation. VXLAN networks are not currently supported in conjunction with SR-IOV on our NIC hardware.
Taking all of the above limitations on board, the same benchamrk between VMs using SR-IOV network port bindings:
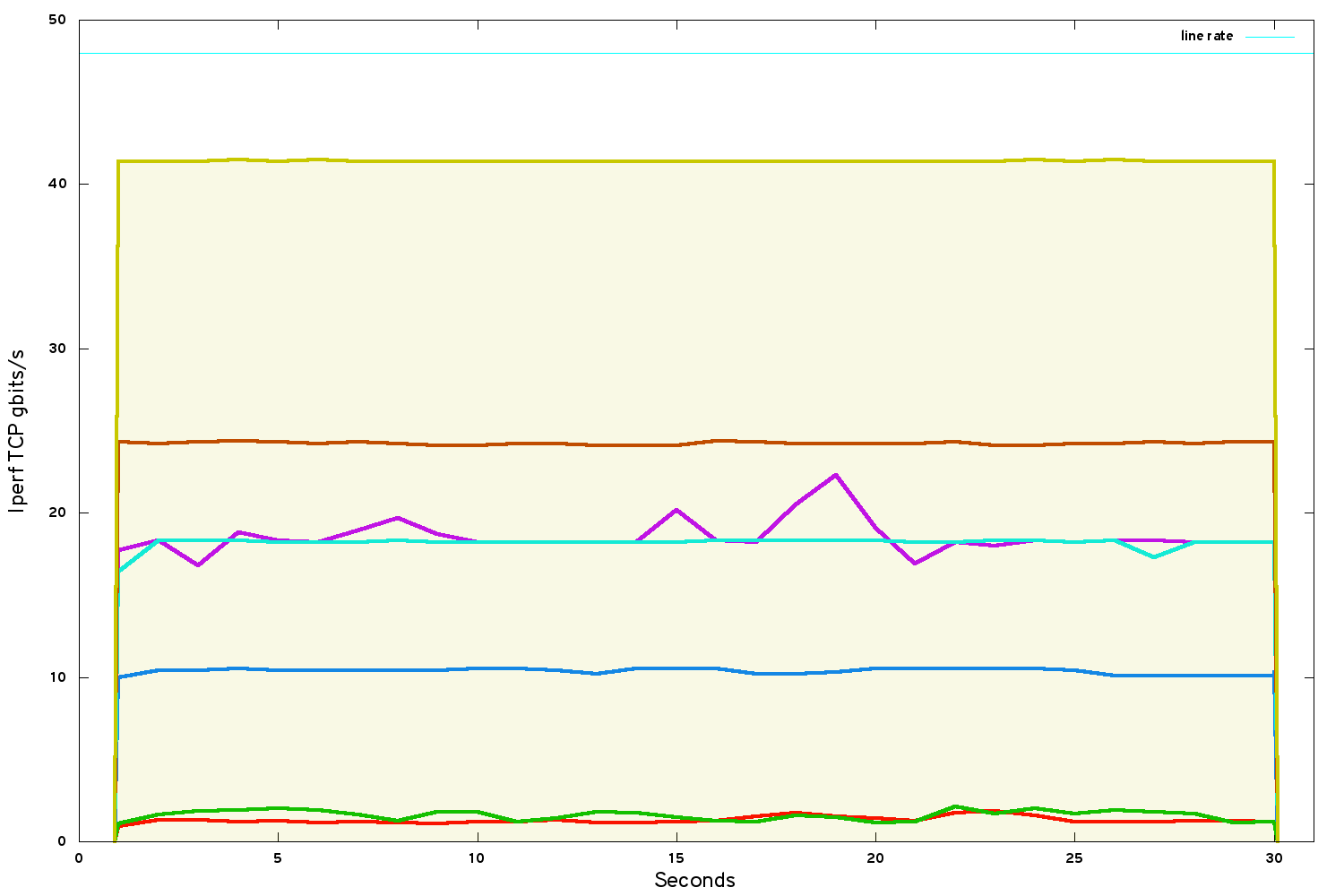
Our bandwidth has raised to just under 42 gbits/s.
If ultimate performance is the ultimate priority, a bare metal solution using OpenStack Ironic is the best option. Ironic offers a combination of the performance of bare metal with (some of) the flexibility of software-defined infrastructure:
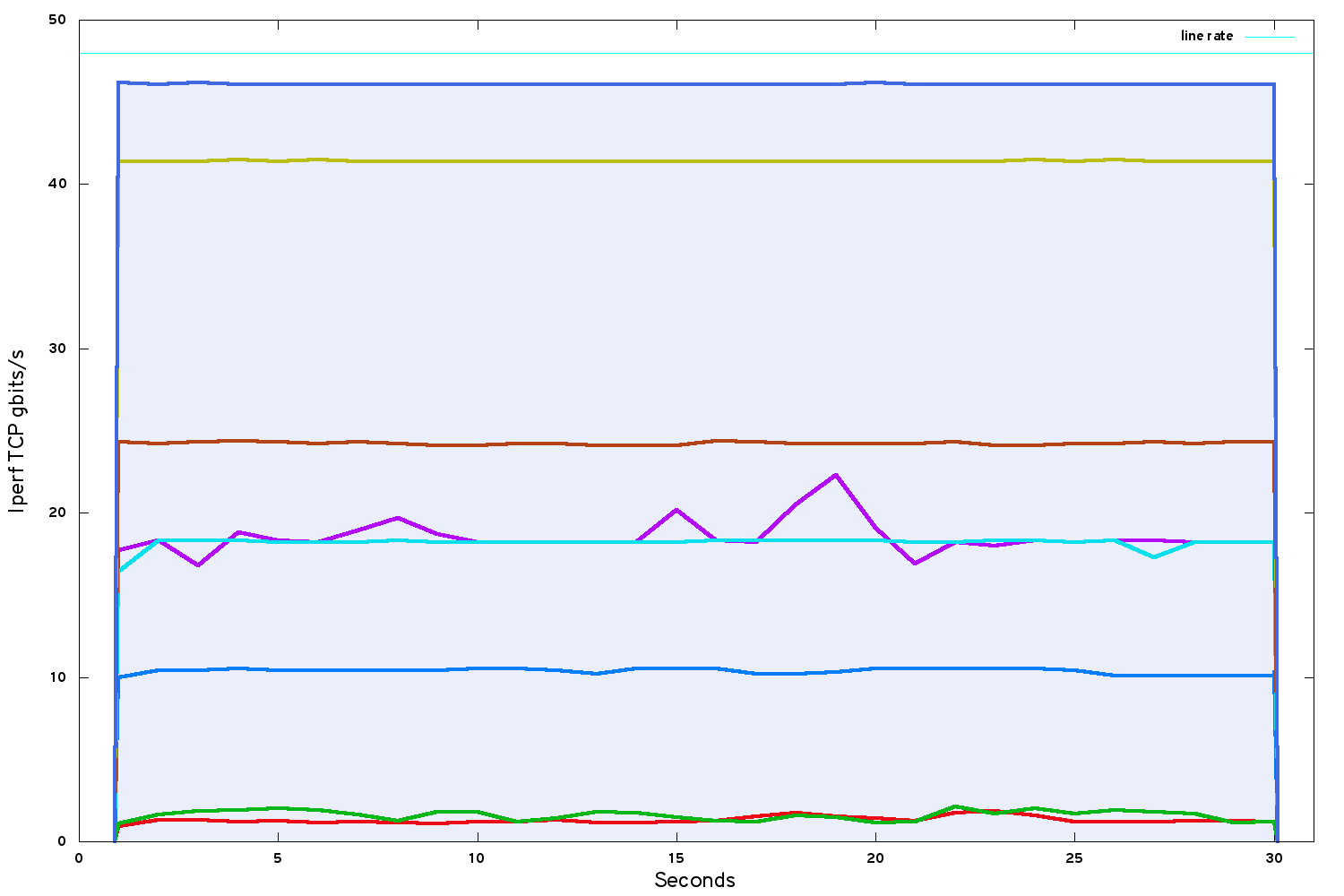
46 gbits/s on a single TCP stream, rising to line rate for multiple TCP streams. Not bad!
The Road Ahead is Less Rocky
The kernel upgrade we performed restricts this investigation to being an experimental result. For customers in production there is always a risk in adopting advanced kernels, and doing so will inevitably break the terms of commercial support.
However, for people in the same situation there are grounds for hope. RHEL 7.3 (and CentOS 7.3) kernels include a back-port of the capabilities we were using for supporting hardware offloading of encapsulated traffic. We will be using this when our control plan gets upgraded to 7.3. For Ubuntu users the Xenial hardware enablement kernel is a 4.x kernel.
Further ahead, a more powerful solution is being developed for Mellanox ConnectX4-LX NICs. Mellanox are calling it Accelerated Switching and Packet Processing (ASAP2). This technology uses the embedded eSwitch in the Mellanox NIC as a hardware offload of OVS. SR-IOV capabilities can then be used instead of paravirtualised virtio NICs in the VMs. The intention is that it should be transparent to users. The code to support ASAP2 must first make its way upstream before it will appear in production OpenStack deployments. We will follow its progress with interest.
Acknowledgements
Thanks go to Scientific Working Group colleagues Blair Bethwaite and Mike Lowe for sharing information and guidance on what works for them.
Throughout the course of this investigation I worked closely with Mellanox support and engineering teams, and I'm hugely grateful to them for their input and assistance.