For optimal reading, please switch to desktop mode.
Convergence of HPC and Cloud will not stop at the infrastructure level. How can applications and users take the greatest advantage from cloud-native technologies to deliver on HPC-native requirements? How can we separate true progress from a blind love of the shiny?
The last decade has continued the rapid movement toward the consolidation of hardware platforms around common processor architectures and the adoption of Linux as the defacto base operating system, leading to the emergence of large scale clusters applied to the HPC market. Then came the adoption of elastic computing concepts around AWS, OpenStack, and Google Cloud. While these elastic computing frameworks have been focused on the ability to provide on-demand computing capabilities, they have also introduced the powerful notion of self-service software deployments. The ability to pull from any number of sources (most commonly open source projects) for content to stitch together powerful software ecosystems has become the norm for those leveraging these cloud infrastructures.
The quest for ultimate performance has come at a significant price for HPC application developers over the years. Tapping into the full performance of an HPC platform typically involves integration with the vendor’s low-level “special sauce”, which entails vendor lock-in. For example, developing and running an application on an IBM Blue Gene system is significantly different than HP Enterprise or a Cray machine. Even in cases where the processor and even the high-speed interconnects are the same, the operating runtime, storage infrastructure, programming environment, and batch infrastructure are likely to be different in key respects. This means that running the same simulations on machines from different vendors within or across data centers requires significant customization effort. Further, the customer is at the mercy of the system vendor for software updates to the base operating systems on the nodes or programming environment libraries, which in many cases significantly inhibits a customer’s ability to take advantage of the latest updates to common utilities or even entire open source component ecosystems.
For these and other reasons reasons, HPC customers are now clamoring for the ability to run their own ‘user defined’ software stacks using familiar containerized software constructs.
The Case for Containers
Containers hold great promise for enabling the delivery of user-defined software stacks. We have covered the state of HPC containers in a previous post.
Cloud computing users are given the freedom to leverage a variety of pre-packaged images or even build their own images and deploy them into their provisioned compute spaces to address their specific needs. Container infrastructures have taken this a step further by leveraging the namespace isolation capabilities of contemporary Linux kernels to provide light-weight, efficient, and secure packaging and runtime environment in which to execute sophisticated applications. Container images are immutable and self-sufficient, which make them very portable and for the most part immune to the OS distribution on which they are deployed.
Kubernetes - Once More Unto the Breach...
Over recent years, containerization (outside of HPC) has consolidated around two main technologies, Docker and Kubernetes. Docker provides a core infrastructure for the construction and maintenance of software stacks, while Kubernetes provides a robust container orchestrator that manages the coordination and distribution of containerized applications within a distributed environment.
Kubernetes has risen to the top in the challenge to provide orchestration and management for containerized software components due to its rich ecosystem and scaling properties. Kubernetes has shown to be quite successful for cloud-native workloads, high-throughput computing and data analytics workflows. But what about conventional HPC workloads? As we will discuss below, there are some significant challenges to the full integration of Kubernetes with the conventional HPC problem space but is there a path to convergence?
A Bit of History
To understand the challenges facing the full adoption of open container ecosystems for HPC, it is helpful to present some of the unique needs of this problem space. We’ve provided a survey of the current state of containers in HPC in a previous blog post.
Taxonomy of HPC Workloads
Conventionally, HPC workloads have been made up of a set of purpose-driven applications designed to solve specific scientific simulations. These simulations can consist of a series of small footprint short-lived ‘experiments’, whose results are aggregated to obtain a particular target result; or large-scale, data-parallel applications that can execute across many thousands of nodes within the system. These two types of applications are commonly referred to as capability and capacity applications.
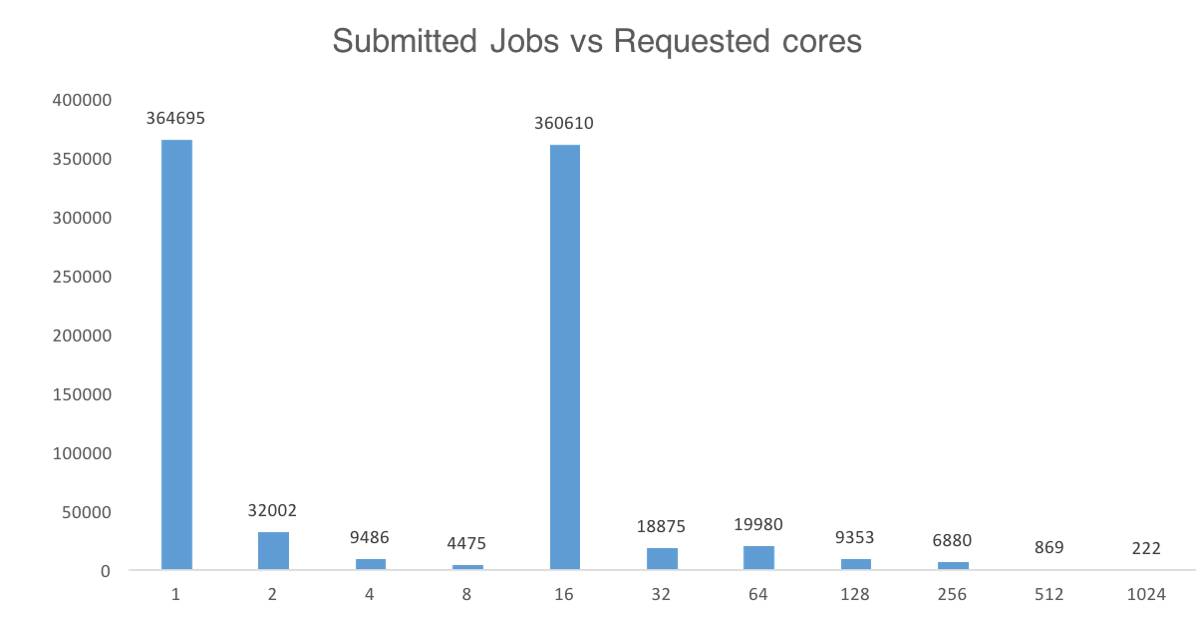
Data from an operational HPC cluster demonstrating that dominant usage of this resource is for sequential or single-node multi-threaded workloads. What is not shown here is that the large-scale parallel workloads have longer runtimes, resulting in a balanced mix of use cases for the infrastructure.
Capability computing refers to applications built to leverage the unique capabilities or attributes of an HPC system. This could be a special high performance network with exceptional bisection bandwidth to support large scale applications, nodes with large memory capacity or specialized computing capabilities of the system (e.g., GPUs) or simply the scale of the system that enables the execution of extreme-scale applications. Capacity computing, on the other hand, refers to the ability of a system to hold large numbers of simultaneous jobs, essentially providing extreme throughput of small and modest sized jobs from the user base.
There are several critical attributes that HPC system users and managers demand to support an effective infrastructure for these classes of jobs. A few of the most important include:
High Job Throughput
Due to the significant financial commitment required to build and operate large HPC systems, the ability to maximize these resources on the solution of real science problems is critical. In most HPC data centers, accounting for the utilization of system resources is a primary focus of the data center manager. For this reason, much work has been expended on the development of Workload Managers (WLMs) to efficiently and effectively schedule and manage large numbers of application jobs on to HPC systems. These WLMs sometimes integrate tightly with system vendor capabilities for advanced node allocation and task placement to ensure most effective use of the underlying computing resource.
Low Service Overhead
For research scientists, time to solution is key. One important example is weather modeling. Simulations have a very strict time deadline as results must be provided in a timely way to release to the public. The amount of computing capacity available to apply to these simulations directly impacts the accuracy, granularity and scope of the results that can be produced.
Such large-scale simulations are commonly referred to as data parallel applications. These applications typically process a large data set manageable pieces, spread in parallel across many tasks. Parallelism occurs both within nodes and between nodes - for which data is exchanged between tasks over high speed networking fabrics using communication libraries such as Partitioned Global Address Space (PGAS) or Message Passing Interface (MPI).
These distributed applications are highly synchronized and typically exchange data after some fixed period of computation. Due to this synchronization, they are very sensitive to, amongst other things, drift between the tasks (nodes). Any deviation by an individual node will often cause a delay in the continuation of the overall simulation. This deviation is commonly referred to as jitter. A significant amount of work has been done to mitigate or eliminate such effects within HPC software stacks. So much so, that many large HPC system manufacturers have spent significant resources to identify and eliminate or isolate tasks that have the potential to induce jitter in the Linux kernels that they ship with their systems. As customers reap direct benefit from these changes, it would be expected that any containerized infrastructure would be assumed to carry forward similar benefits. This would presume that any on-node presence supporting container scheduling or deployment would present minimal impact to the application workload.
Advanced Scheduling Capabilities
Many HPC applications have specific requirements relative to where they are executed within the system. Where each task (rank) of an application may need to communicate with specific neighboring tasks and so prefer to be placed topologically close to these neighbors to improve communication with these neighbors. Other tasks within the application may be sensitive to the performance of the I/O subsystem and as such may prefer to be placed in areas of the system where I/O throughput or response times are more favorable. Finally, individual tasks of an application may require access to specialized computing hardware, including nodes with specific processor types attached processing accelerators (e.g., GPUs). What’s more, individual threads of a task are scheduled in such a way as to avoid interference by work unrelated to the user’s job (e.g., operating system services or support infrastructure, such as monitoring). Interference with the user’s job by these supporting components has a direct and measurable impact on overall job performance.

The Role of PMI(x)
The Message Passing Interface (MPI) is the most common mechanism used by data-parallel applications to exchange information. There are many implementations of MPI, ranging from OpenMPI, which is a community effort, to vendor-specific MPI implementations, which integrate closely with vendor-supplied programming environments. One key building block on which all MPI implementations are built is the Process Management Interface (PMI). PMI provides the infrastructure for an MPI application to distribute the information about all of the other participants across an entire application.
PMI is a standardized interface which has gone through a few iterations each with improvements to support increased job scale with reduced overhead. The most recent version, PMIx is an attempt to develop a standardized process management library capable of supporting the exchange of connection details for applications deployed on exascale systems reaching upwards of 100K nodes and a million ranks. The goal of the project is to achieve this ambitious scaling without compromising the needs of more modest sized clusters. In this way, PMIx intends to support the full range of existing and anticipated HPC systems.
Early evaluation of launch performance in the wire-up phase of PMIx is quite illuminating as can be seen from this SuperComputing '17 presentation. This presentation shows the performance advantages in launch times as the number of on-node ranks increases by utilizing a native PMIx runtime TCP interchange to distribute wire-up information rather than using Slurm’s integrated RPC capability. The presentation then goes on to show how an additional two orders of magnitude improvement by leveraging native communication interfaces of the platform through the UCX communication stack. While this discussion isn’t intended to focus on the merits of one specific approach over another for launching and initializing a data parallel application, it does help to illustrate the sensitivity of these applications to the underlying distributed application support infrastructure.
Full Integration of Open Container Frameworks with Conventional HPC Workflows
There are projects underway with the goal of integrating Kubernetes with MPI. One notable approach, kube-openmpi, uses Kubernetes to launch a cluster of containers capable of supporting the target application set. Once this Kubernetes namespace is created, it is possible to use kubectl to launch and mpiexec applications into the namespace and leverage the deployed OpenMPI environment. (kube-openmpi only supports OpenMPI, as the name suggests).
Another framework, Kubeflow, also supports execution of MPI tasks atop Kubernetes. Kubeflow’s focus is evidence that the driving force for MPI-Kubernetes integration will be large-scale machine learning. Kubeflow uses a secondary scheduler within Kubernetes, kube-batch to support the scheduling and uses OpenMPI and a companion ssh daemon for the launch of MPI-based jobs.
While approaches such as kube-openmpi and kubeflow provide the ability to launch MPI-based applications as Kubernetes jobs atop a containerized cluster, they essentially replicate existing *flat earth* models for data-parallel application launch within the context of an ephemeral container space. Such approaches do not fully leverage the flexibility of the elastic Kubernetes infrastructure, or support the critical requirements of large-scale HPC environments, as described above.
In some respects, kube-openmpi is another example of the fixed use approach to the use of containers within HPC environments. For the most part there have been two primary approaches. Either launch containers into a conventional HPC environment using existing application launchers (e.g., Shifter, Singularity, etc.), or emulate a conventional data parallel HPC environment atop a container deployment (à la kube-openmpi).
While these approaches are serviceable for single-purpose environments or environments with relatively static or purely ephemeral use cases, problems arise when considering a mixed environment where consumers wish to leverage conventional workload manager-based workflows in conjunction with a native container environment. In cases where such a mixed workload is desired, the problem becomes how to coordinate the submission of work between the batch scheduler (e.g., Slurm) and the container orchestrator (e.g., Kubernetes).
Another approach to this problem is to use a meta-scheduler that coordinates the work across the disparate domains. This approach has been developed and promoted by Univa through their Navops Command infrastructure. Navops is based on the former Sun Grid Engine, originally developed by Sun Microsystems, then acquired by Oracle, and eventually landing at Univa.
While Navops provides an effective approach to addressing these mixed use coordination issues, it is a proprietary approach and limits the ability to leverage common and open solutions across the problem space. Given the momentum of this space and the desire to leverage emerging technologies for user-defined software stacks without relinquishing the advances made in the scale supported by the predominant workload schedulers, it should be possible to develop cleanly integrated, open solutions which support the set of existing and emerging use cases.

What Next?
So what will it take to truly develop and integrate a fully open, scalable, and flexible HPC stack that can leverage the wealth of capabilities provided by an elastic infrastructure? The following presents items on our short list:
Peaceful Coexistence of Slurm with Kubernetes
Slurm has become the de facto standard for open management of conventional HPC batch-oriented, distributed workloads. Likewise, Kubernetes dominates in the management of flexible, containerized application workloads. Melding these two leading technologies cleanly in a way that leverages the strengths of each without compromising the capabilities of either will be key to the realization of the full potential of elastic computing within the HPC problem space.
Slurm already integrates with existing custom (and ostensibly closed) frameworks such as Cray’s Application Launch and Provisioning System (ALPS). It has been proven through integration efforts such as this that there is significant gain to be made by leveraging capabilities provided by such infrastructures. ALPS has been designed to manage application launch at scale and manage the runtime ecosystem (including network and compute resources) required by large, hero-class applications.
Like these scaled job launchers, Kubernetes provides significant capability for placement, management, and deployment of applications. However, it provides a much richer set of capabilities to manage containerized workflows that are familiar to those who are leveraging cloud-based ecosystems.
While the flexibility of cloud computing allows users to easily spin up a modest-sized set of cooperating resources on which to launch distributed applications, within a conventional HPC infrastructure, designed for the execution of petascale and (coming soon) exascale applications, there are real resource constraints at play that require a more deliberate approach at controlling and managing the allocation and assignment of these resources.
The ability to manage such a conventional workload-based placement strategy in conjunction with emerging container-native workflows has the potential of significantly extending the reach and broadening the utility of high performance computing platforms.
Support for Elasticity within Slurm
Slurm is quite effective in the management of the scheduling and placement of conventional distributed applications onto nodes within an HPC infrastructure. As with most conventional job schedulers, Slurm assumes that it is managing a relatively static set of compute resources. Compute entities (nodes) can come and go during the lifetime of a Slurm cluster. However, Slurm prefers that the edges of the cluster be known apriori so that all hosts can be aware of all others. In other words, the list of compute hosts is distributed to all hosts in the cluster when the Slurm instance is initialized. Slurm then manages the workload across this set of hosts. However, management of a dynamic infrastructure within Slurm can be a challenge.
Mediation of Scheduler Overhead
There is a general consensus that there are tangible advantages to the use of on-demand computing to solve high performance computing problems. There is also general consensus that the flexibility of an elastic infrastructure brings with it a few undesirable traits. The one that receives the most attention is added overhead. Any additional overhead has a direct impact on the usable computing cycles that can be applied by the target platform to the users’ applications. The source of that overhead, however, is in the eye of the beholder. If you ask someone focused on the delivery of containers, they would point to the bare-metal or virtual machine infrastructure management (e.g., OpenStack) as a significant source of this overhead. If you were to ask an application consumer attempting to scale a large, distributed application, they would likely point at the container scheduling infrastructure (e.g., Kubernetes) as a significant scaling concern. For this reason, it is common to hear comments like, “OpenStack doesn’t scale”, or “Kubernetes doesn’t scale”. Both are true… and neither are true. It really depends on your perspective and the way in which you are trying to build the infrastructure.
This attitude tends to cause a stovepiping of solutions to address specific portions of the problem space. What is really needed is a holistic view, covering a range of capabilities and solutions and a concerted effort to provide integrated solutions. An ecosystem that exposes the advantages of each of the components of elastic infrastructure management, containerized software delivery, and scaled, distributed application support, while providing seamless coexistence of familiar workflows across these technologies would provide tremendous opportunities for the delivery of high performance computing solutions into the next generation.
If you would like to get in touch we would love to hear from you. Reach out to us via Twitter or directly via our contact page.